Instalasi Hadoop Cluster di Ubuntu 14.04 VMWare [Bagian 2]

Berikut ini adalah langkah berikutnya dari instalasi Hadoop Cluster di Ubuntu 14.04 VMWare. Untuk langkah sebelumnya bisa dilihat di Bagian 1.
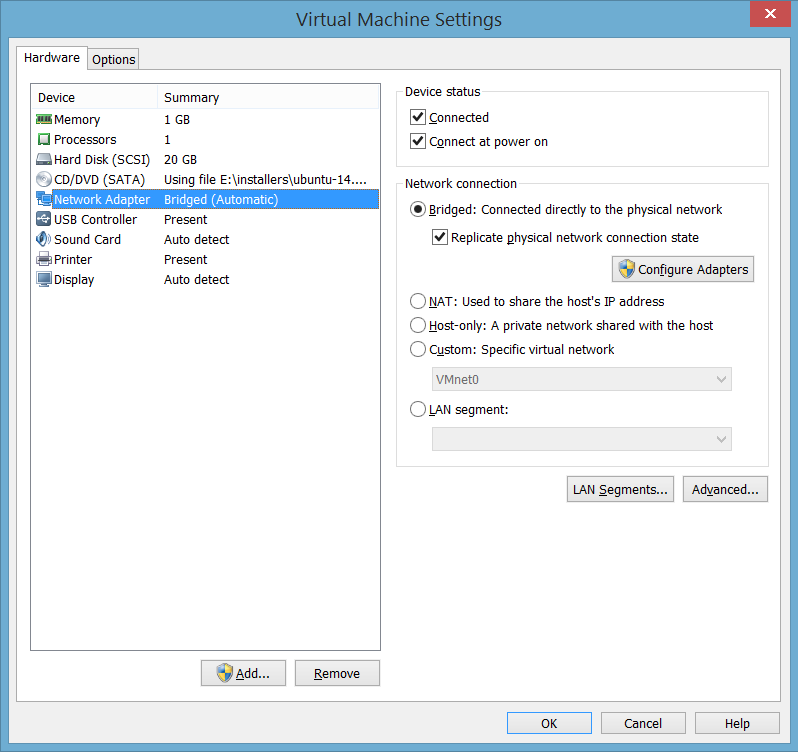
9. Duplikasi Ubuntu InstanceUntuk membuat 3 instance server ubuntu, shutdown VMWare, dan kopi direktori tempat file-file VM Image tersebut dua kali. Untuk mengetahui letak direktori, buka menu Player → Manage → Virtual Machine Setting di bagian Working Directory
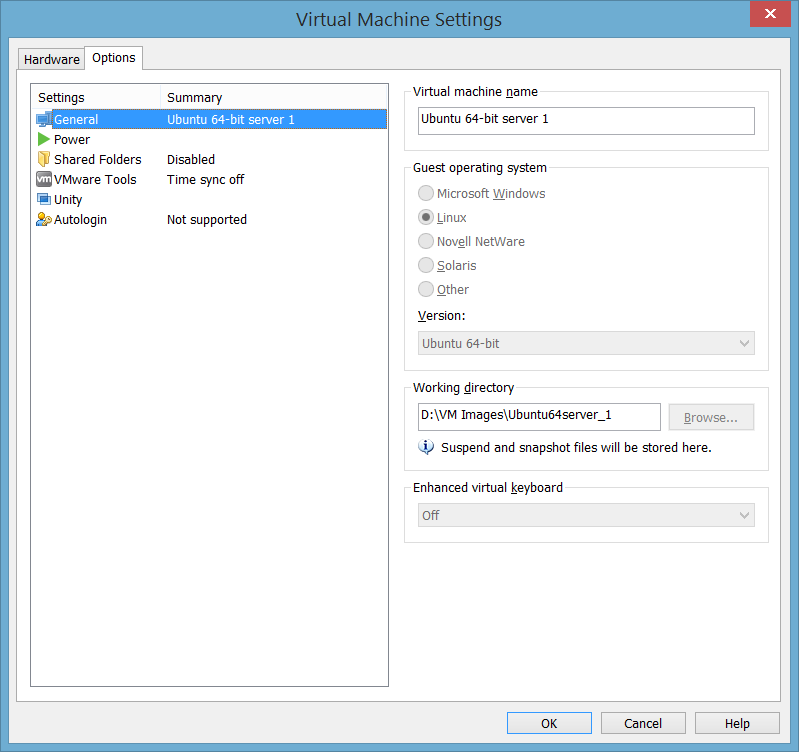
re, dan kopi direktori tempat file-file VM Image tersebut dua kali. Untuk mengetahui letak direktori, buka menu Player → Manage → Virtual Machine Setting di bagian Working Directory
Selanjutnya, jalankan VMWare Player, pilih menu Open a Virtual Machine. Buka file .vmx di ke 2 direktori hasil copy tersebut, dan pilih Play virtual Machine. Anda akan mendapatkan dialog box
10. Setting koneksi
Ada beberapa hal yang perlu dilakukan, yaitu setting hostname di file /etc/hostname, setting mapping hostname di file /etc/hosts, dan setting ssh connection.Setting hostname
Buka 3 Virtual machine tersebut, ubah nama masing-masing menjadi ubuntu1, ubuntu2 dan ubuntu 3, dengan cara edit file /etc/hostname :
hduser@ubuntu:~$ sudo vi /etc/hostnameMisalnya untuk server ubuntu3 menjadi sbb:

Edit file /etc/hosts di ke 3 server sbb:
Server 1 : ubuntu1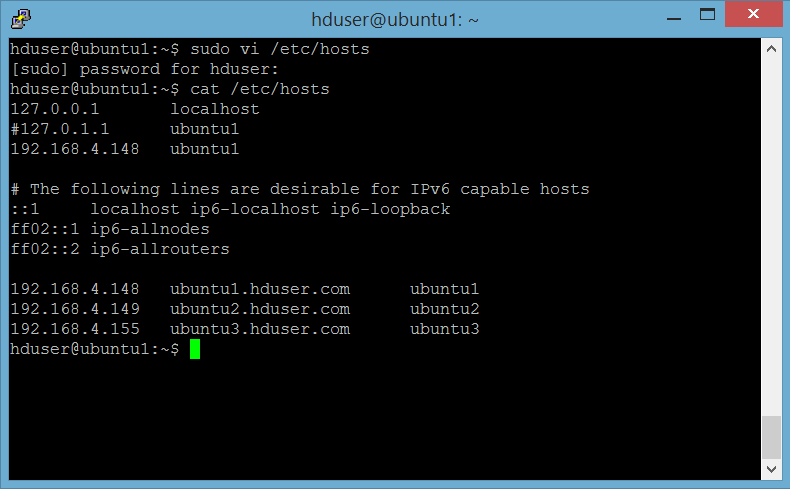
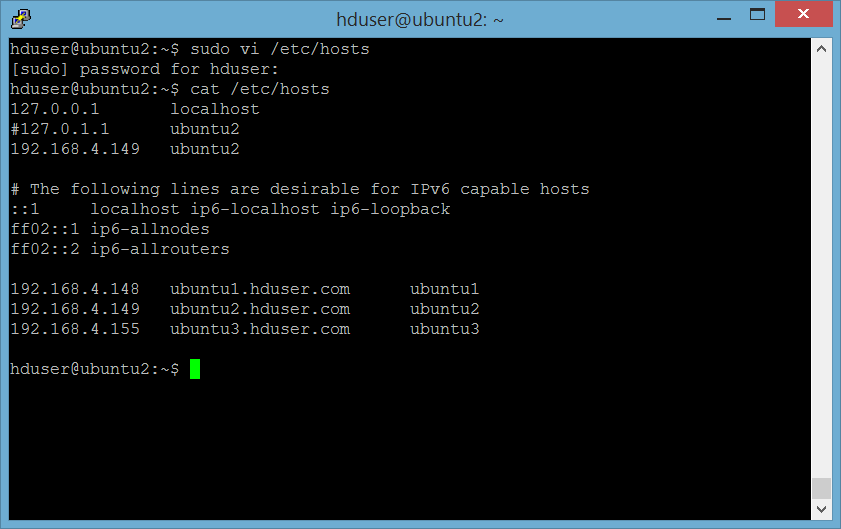
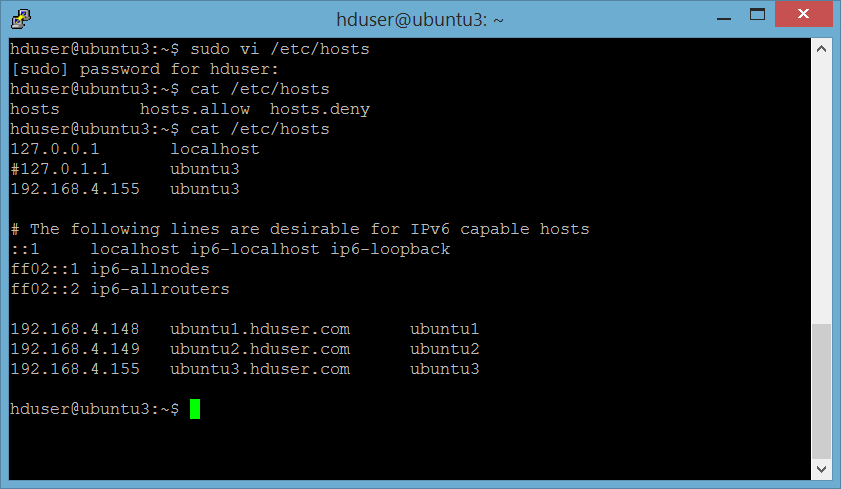

Lakukan di ke 3 server.
Setting sshDi server ubuntu1, lakukan:
hduser@ubuntu1:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu2hduser@ubuntu1:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu3
Untuk mengetes koneksi, lakukan :
hduser@ubuntu1:~$ ssh hduser@ubuntu2hduser@ubuntu1:~$ ssh hduser@ubuntu2
Seharusnya sudah tidak diminta password untuk ssh tersebut.
Di server ubuntu2 dan ubuntu3, lakukan:hduser@ubuntu2:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu1
Untuk mengetes koneksi, lakukan :
hduser@ubuntu2:~$ ssh hduser@ubuntu1Seharusnya sudah tidak diminta password untuk ssh tersebut.
11. Format HDFS file systemLakukan ini di namenode (server ubuntu1) pada pertama kali instalasi. Jangan melakukan namenode format untuk Hadoop yang sudah berjalan (berisi data), karena perintah format ini akan menghapus semua data di HDFS, dan kemungkinan akan membuat hdfs dalam cluster anda tidak konsisten satu sama lain (namenode dan data node).
hduser@ubuntu1:$ hdfs namenode -formatOutputnya akan seperti berikut ini:
|
hduser@ubuntu1:$ /usr/local/hadoop/bin/hadoop namenode -format
10/05/08 16:59:56 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = ubuntu/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010 ************************************************************/ 10/05/08 16:59:56 INFO namenode.FSNamesystem: fsOwner=hadoop,hadoop 10/05/08 16:59:56 INFO namenode.FSNamesystem: supergroup=supergroup 10/05/08 16:59:56 INFO namenode.FSNamesystem: isPermissionEnabled=true 10/05/08 16:59:56 INFO common.Storage: Image file of size 96 saved in 0 seconds. 10/05/08 16:59:57 INFO common.Storage: Storage directory .../hadoop-hadoop/dfs/name has been successfully formatted. 10/05/08 16:59:57 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1 ************************************************************/ hduser@ubuntu1:$ |
12. Start HDFS dan Yarn
Lakukan ini di namenode (server ubuntu1).Start hdfs :
hduser@ubuntu1:$ /usr/local/hadoop/sbin/start-dfs.sh
hduser@ubuntu1:$ /usr/local/hadoop/sbin/start-yarn.sh

Untuk memastikan data node sudah berjalan dengan baik, di data node server (ubuntu2 dan ubuntu3), cek log di /usr/local/hadoop/logs/hadoop-hduser-datanode-ubuntu2.log dan /usr/local/hadoop/logs/hadoop-hduser-datanode-ubuntu3.log
ika anda mendapatkan message seperti berikut ini:2015-11-10 12:35:53,154 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: ubuntu1/192.168.4.148:54310
Maka pastikan bahwa setting /etc/hosts di ke 3 server sudah dilakukan dengan benar seperti di poin 10 di atas (Setting Koneksi). Cek ip masing-masing server dengan perintah ifconfig. Cek service di masing-masing server dengan perintah jps.
12. Test HDFSUntuk memastikan semua node sudah naik dan berfungsi dengan baik, kita akan meng-upload file test ke dfs. Lakukan perintah berikut ini di server name node (ubuntu1):
buat direktori /data di hdfshadoop fs -mkdir /data
upload file /usr/local/hadoop/README.txthadoop fs -put /usr/local/hadoop/README.txt /data/README.txt

13. Hadoop Web Interface
Anda dapat mengakses hadoop web interface dari browser anda, dengan mengakses namenode:50070. Akan tampil halaman seperti berikut ini.
Dari keterangan di atas terlihat bahwa terdapat 2 data nodes yang hidup dan terhubung. Klik menu Datanodes untuk melihat informasi lebih detail mengenai kedua data node tersebut:

File yang kita buat tadi akan terlihat di menu Utilities → Browse the file system

Demikianlah tutorial instalasi Hadoop kali ini, semoga bermanfaat.
Nantikan tutorial berikutnya 🙂
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.