Apache, Big Data, Implementation, Medical Analytics


Seputar Big Data Edisi #32
Kumpulan berita, artikel, tutorial dan blog mengenai Big Data yang dikutip dari berbagai site. Berikut ini beberapa hal menarik yang layak untuk dibaca kembali selama minggu ke 4 bulan September 2017
Artikel dan berita
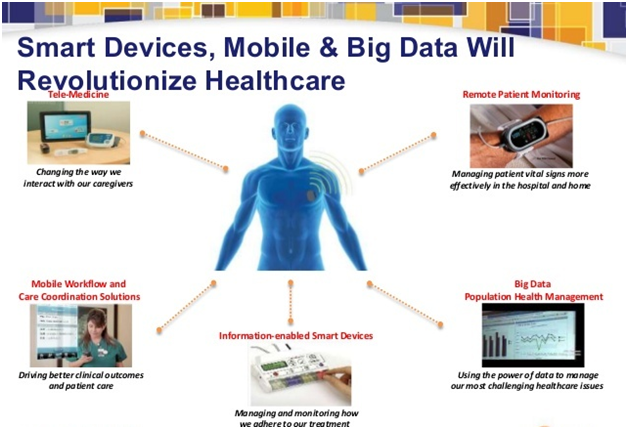
- Using Big Data Medical Analytics To Address The Opioid Crisis
Overdosis obat di tahun 2016, terutama yang berkaitan dengan opioid, menewaskan lebih dari 64 ribu orang di Amerika. Menurut CDC, jumlah tersebut merupakan kenaikan 21% dari tahun 2015. Krisis opioid merupakan problem yang dilematis, karena permasalahannya tidak hanya pada peredaran obat ilegal, namun juga peredaran resmi (obat yang diresepkan). Salah satu sarana yang dianggap dapat menjadi pendukung untuk mengatasi krisis ini adalah penggunaan big data medical analytics. Apa saja peluang dan tantangannya? - Hadoop Was Hard to Find at Strata This Week
Tidak hanya menghilang dari judul konferensi, dalam acara Strata Data (yang sebelumnya bernama Strata Hadoop), Hadoop pun terkesan menghilang dari peredaran. Banyak yang mengatakan bahwa hal ini terjadi karena “Spark membunuh Hadoop”. Apakah benar demikian? Bagaimana trend ke depannya? -
How to Select a Big Data Application
Memilih software big data bisa menjadi sebuah proses yang rumit dan memerlukan pertimbangan yang matang, berdasar tujuan dan solusi yang tersedia. Artikel ini mencoba mengupas jenis-jenis solusi big data dan karakteristik apa yang perlu dipertimbangkan dalam memilihnya.
Tutorial dan Pengetahuan Teknis
-
XGBoost, a Top Machine Learning Method on Kaggle, Explained
XBoost atau eXtreme Gradient Boosting, adalah salah satu tools yang paling populer di kalangan kompetitor Kaggle dan data saintist, dan telah diujicoba dalam implementasi skala besar. XBoost bersifat fleksibel dan versatile, dan dapat digunakan untuk menangani hampir semua kasus regresi, klasifikasi dan ranking, serta fungsi buatan user. Sebagai sebuah software open source, XBost mudah diakses dan dapat digunakan di atas berbagai platform dan antarmuka. Artikel ini mencoba menjelaskan mengenai apa XBoost tersebut, dan apa saja kelebihannya. -
Comparison API for Apache Kafka
Dalam artikel ini disajikan berbagai penerapan Kafka API, mulai dari consume data dari stream, menulis ke stream, sampai pendekatan yang lebih reaktif menggunakan Akka. -
PyTorch tutorial distilled – Migrating from TensorFlow to PyTorch
Artikel yang mengupas dengan baik dan menarik mengenai PyTorch, dan tutorial mengenai bagaimana melakukan migrasi dari TensorFlow ke PyTorch. -
[FREE EBOOK] Deep Learning – By Ian Goodfellow, Yoshua Bengio and Aaron Courville
“Deep Learning” adalah teksbook yang ditujukan untuk membantu mahasiswa dan praktisi untuk memasuki bidang machine learning, dan khususnya deep learning. Versi online dari buku ini sudah lengkap dan dapat diakses secara gratis. -
[DATASET] NIH Clinical Center provides one of the largest publicly available chest x-ray datasets to scientific community
Pusat klinis NIH menyediakan dataset berupa hasil x-ray dada, yang bisa diakses oleh publik. Dataset ini berisi lebih dari 100.000 x-ray image, dari sekitar 30.000 pasien, termasuk di antaranya dengan berbagai penyakit paru-paru yang berat.
Rilis Produk
-
Apache NiFi 1.4.0 Released
Versi 1.4.0 ini adalah rilis fitur dan stabilitas, menekankan pada bug fixes yang penting dan penambahan prosesor dan controller services baru. Beberapa fitur baru di antaranya adalah support untuk Apache Knox, autorisasi grup dengan Apache Ranger, dan LDAP-base user authentication. -
Apache Solr Reference Guide for 7.0 released
Setelah Solr 7.0 dirilis beberapa waktu yang lalu, Reference Guide Solr 7.0 dirilis minggu lalu. Dokumen yang berupa 1.035 halaman file PDF berisi dokumentasi untuk fitur-fitur baru, dengan daftar lengkap perubahan konfigurasi dan deprecation yang penting untuk diperhatikan untuk melakukan upgrade dari Solr versi sebelumnya. -
Theano To Cease Development After Version 1.0
Theano, library komputasi numerik untuk Python yang merupakan pelopor di dunia machine learning, akan segera merilis versi 1.0, namun bersamaan dengan itu diumumkan bahwa kegiatan pengembangan Theano akan berakhir setelahnya. Support minimal akan dilanjutkan selama 1 tahun, dan selanjutnya sebagai open source Theano akan tetap dapat diakses bebas, namun tanpa support dari MILA. -
Yahoo open-sources Vespa, its most important software release since Hadoop
Oath, anak perusahaan yang dibentuk ketika Verizon Communication Inc. mengakuisisi Yahoo, membuka salah satu komponen software yang berperan penting dalam melakukan web search dan men-generate rekomendasi dan iklan. Software yang di-open source-kan tersebut bernama Vespa, digunakan untuk menangani permasalahan yang ‘tricky’ dalam hal menentukan apa yang harus ditampilkan sebagai respon dari input user. Oath menggunakan Vespa untuk lebih dari 150 aplikasinya, termasuk Flickr.com, Yahoo Mail dan beberapa aspek dari Yahoo search engine.
Contributor :
Tim idbigdata
always connect to collaborate every innovation
always connect to collaborate every innovation