[Belajar Machine Learning 2] Loading dan Eksplorasi Data dengan Pandas dan Scikit-Learn

Cara paling cepat untuk menguasai sebuah tool atau platform adalah dengan membuat sebuah end-to-end project yang mencakup langkah-langkah utama dalam implementasi machine learning. Langkah tersebut antara lain adalah : loading data, summary data, evaluasi algoritma dan membuat beberapa prediksi.
Membuat end-to-end project berarti membiasakan diri dengan proses machine learning, dan kasus yang telah dikerjakan dapat menjadi semacam template yang bisa digunakan untuk mengolah berbagai dataset lainnya.
Untuk memulainya tidak perlu menggunakan dataset atau kasus yang terlalu rumit. Anda bisa memilih data yang tersedia di dalam library scikit-learn. Daftar lengkap datasetnya dapat dilihat di sini.
Dalam artikel ini akan digunakan dataset iris sebagai contoh kasusnya.
Dataset iris ini sangat sesuai untuk latihan karena :
- Ukurannya tidak terlalu besar, yaitu 4 atribut dan 150 row, sehingga tidak akan membebani memori
- Atributnya sederhana. Seluruh atribut numerik dalam unit dan skala yang sama, sehingga tidak memerlukan transformasi khusus
Meskipun teknik dan prosedur dalam penerapan machine learning sangat bervariasi, namun secara garis besar sebuah project machine learning memiliki tahapan sebagai berikut:
- Definisi masalah
- Menyiapkan data
- Memilih/mengevaluasi algoritma
- Melakukan tuning untuk memperbaiki hasil
- enyajikan hasil
Salah satu hal yang paling penting dalam langkah-langkah awal project adalah memahami data. Dalam artikel ini akan disajikan mengenai loading dan beberapa fungsi eksplorasi data untuk melihat bagaimana dataset yang akan kita proses nantinya.
1. Cek Instalasi
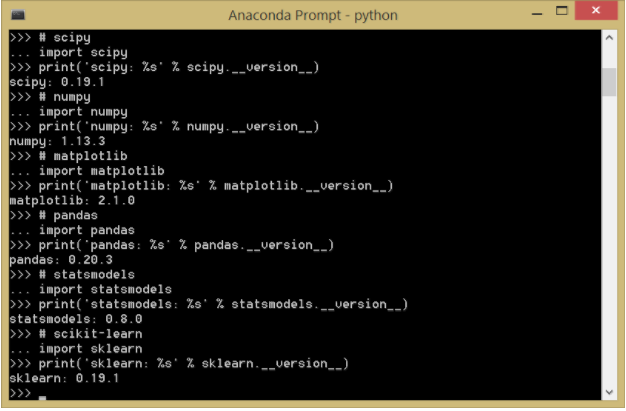
Jalankan perintah-perintah berikut untuk mengecek versi package yang terinstall.
Versi yang package yang akan gunakan mestinya lebih baru atau setidaknya sama dengan yang terdapat pada output di bawah ini. Jika versi package anda sedikit tertinggal, mestinya tidak masalah, karena biasanya API-nya tidak terlalu banyak berubah. Anda masih dapat menjalankan code yang ada dalam latihan di bawah ini. Tapi jika ingin memperbaharui package yang ada, langkah update package dapat dilihat di posting sebelumnya.

Output yang didapatkan kurang lebih sbb (versi bisa berbeda):

Berikutnya adalah loading package yang akan digunakan. Lakukan import untuk mengecek apakah instalasi sudah ok. Jika terdapat error, stop dan resolve. Package di bawah ini perlu untuk menjalankan latihan dalam artikel ini.
Petunjuk setting environment bisa dilihat di posting sebelumnya. Jika terdapat pesan error yang spesifik, anda bisa mencari cara resolve-nya di forum-forum seperti Stack Exchange (http://stackoverflow.com/questions/tagged/python).
2. Loading Data
Jika langkah di atas berjalan dengan baik, load dataset iris dari package sklearn dengan menjalankan fungsi berikut:

Tips : Untuk mengetahui jenis sebuah object atau fungsi dalam python, kita bisa mengetikkan nama object atau fungsi yang ingin kita ketahui, diikuti tanda tanya, seperti pada contoh berikut :

Outputnya adalah informasi dari object tersebut, seperti berikut:
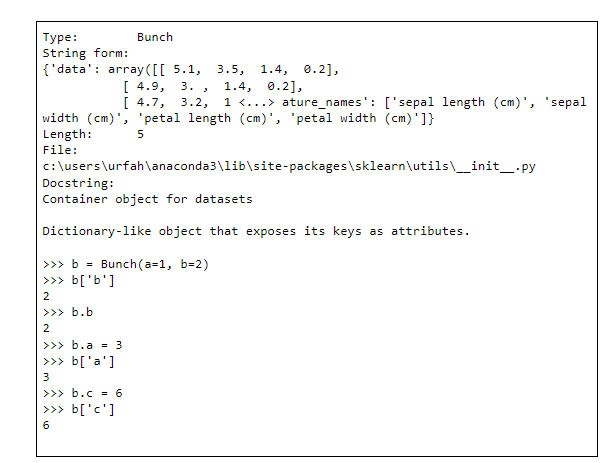
Untuk mengetahui apa saja yang terdapat di dalam dataset iris, tampilkan seluruh keys dalam dataset tersebut dengan perintah berikut ini:

Outputnya berupa daftar dari keys atau kata kunci yang terdapat dalam dictionary:

Dari outputnya kita dapat mengetahui bahwa dalam dataset iris terdapat key berikut : data, target, target_name, DESCR dan feature_names. Kita dapat mengakses dan menampilkan value-nya dengan key tersebut. Misalnya untuk menampilkan deskripsi dataset, lakukan sbb:

Output:

Seperti tampak pada deskripsi di atas, dataset iris memiliki 4 atribut numerik : sepal length, sepal width, petal length, dan petal width.
Terdapat 3 jenis spesies (class), yaitu
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
Terdapat 150 entry (150 rows data), yang terbagi rata ke dalam 3 kelas tersebut.
Atribut disimpan di elemen “data”, dan kelas/species di elemen “target”. Keduanya bertipe numerik.
Kita lihat bentuk datanya, dengan ‘mengintip’ beberapa baris data dan target, dengan command berikut:

Dari output di bawah terlihat bahwa format data adalah numerik, dan nilai target menunjukkan indeks dari array target_names.

3. Convert dataset ke dalam Pandas DataFrame
Untuk memudahkan pemrosesan dan eksplorasi data, kita akan mengubah dataset tersebut ke dalam format pandas DataFrame.
Pandas adalah package yang dibangun di atas library numPy. Pandas menyediakan data struktur yang efisien dan fleksibel, yang dirancang untuk melakukan analisis data dalam Python.
Keterangan lebih lanjut mengenai pandas dan berbagai object di dalamnya dapat dilihat di sini (https://pandas.pydata.org/pandas-docs/stable/)
Berikut ini command untuk mengubah dataset iris menjadi Pandas Dataframe:

4. Eksplorasi Dataset
Beberapa hal yang akan kita lakukan adalah :
- Melihat dimensi dataset
- Contoh datanya
- Ringkasan statistik semua atribut
- Mengelompokkan data berdasar variabel target
Yang pertama kita lihat dimensi datanya (jumlah row dan kolom) dengan menggunakan atribut shape

Output:

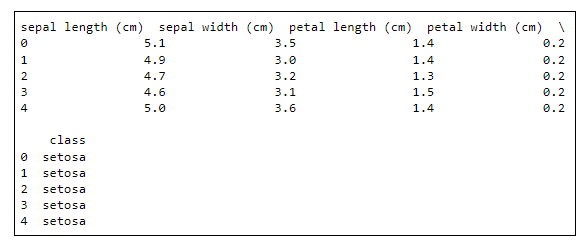
Selanjutnya kita ‘intip’ contoh data dengan menggunakan fungsi head. Dari sini terlihat dataset kita memiliki 4 atribut numerik dan 1 atribut string.

Output:
Statistical Summary
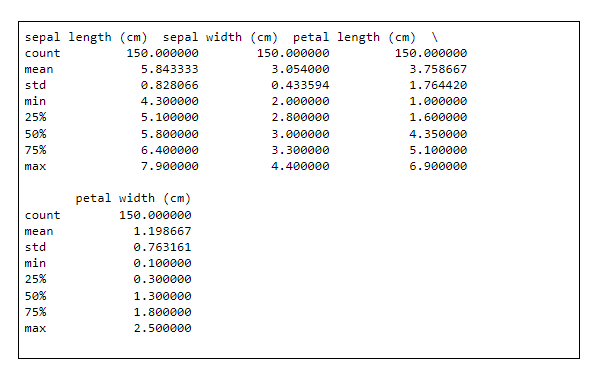
Selanjutnya kita lihat summary setiap atribut dengan fungsi describe. Fungsi ini menampilkan summary statistik untuk atribut numerik dari dataset kita, termasuk di dalamnya count, mean, nilai minimum dan maksimum, serta nilai2 persentilnya.

Dari summary tersebut terlihat bahwa seluruh nilai numerik memiliki skala yang sama (yaitu dalam cm), dan memiliki range yang serupa juga, yaitu antara 0 sampai 8 cm.
Distribusi Data
Bagaimana dengan distribusi datanya? Untuk melihat distribusi data, kita kelompokkan datanya berdasarkan kelas sbb:

Output:

Terlihat bahwa data terbagi menjadi 3 kelas dengan jumlah yang sama, yaitu masing-masing 50 row.
Visualisasi Data
Kita juga dapat melihat ‘bentuk’ data dengan lebih jelas dengan cara memvisualisasikannya. Yang pertama kita bisa melihat distribusi masing-masing atribut dengan menampilkannya dalam bentuk boxplot.


Kita juga bisa melihat sebaran datanya dengan bentuk histogram.

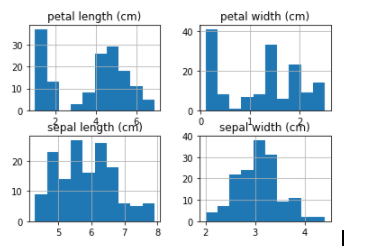
Dari histogram di atas tampak bahwa setidaknya ada 2 variabel yang kemungkinan memiliki sebaran normal. Asumsi ini dapat kita jadikan pertimbangan ketika memilih algoritma nantinya.
Interaksi Antar Variabel
Selanjutnya kita lihat interaksi antara variabel dengan menampilkan scatterplot. Hal ini bermanfaat untuk melihat adanya hubungan antara variabel-variabel input. Indikasi adanya korelasi antar variabel adalah dari pola scatterplot yang membentuk garis diagonal.

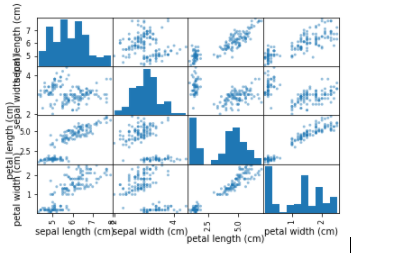
Setelah kita mendapat gambaran mengenai dataset yang akan kita proses, kita siap melakukan testing dan tuning algoritma.
Versi Jupyter notebook dari latihan ini dapat di unduh di :
https://github.com/urfie/belajar-python/blob/master/Belajar%20Machine%20Learning%20-%20Load%20and%20Explore%20Dataset.ipynb
Sumber : https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
Contributor :

Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng.
Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun.
Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.