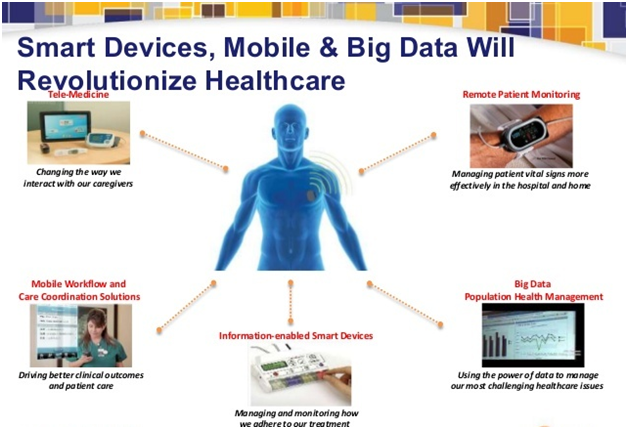
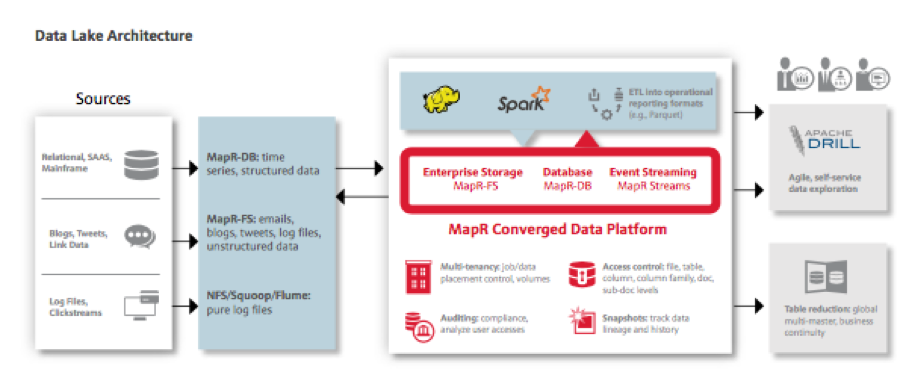
Apache, Big Data, Implementation, Uncategorized


Seputar Big Data Edisi #31
Kumpulan berita, artikel, tutorial dan blog mengenai Big Data yang dikutip dari berbagai site. Berikut ini beberapa hal menarik yang layak untuk dibaca kembali selama minggu ketiga bulan September 2017
Artikel dan Berita
- Japan to certify big-data providers to drive innovation
Pemerintah Jepang mengumumkan rencana untuk melakukan sertifikasi terhadap perusahaan yang mengumpulkan data dari berbagai sumber dan menyediakannya sebagai services. Sertifikasi akan berlaku untuk 5 tahun, dan perusahaan-perusahaan yang disebut sebagai big data banks ini akan mendapatkan keringanan pajak. - Big Data – what’s the big deal for Procurement?
Apa tantangan yang dihadapi oleh bagian procurement saat ini, dan bagaimana peran big data dalam mengatasinya? - The Amazing Ways Burberry Is Using Artificial Intelligence And Big Data To Drive Success
Sejak 2006, Burberry, perusahaan mode terkemuka asal Inggris, memutuskan untuk menjadi sebuah perusahaan digital “end to end”. Strategi yang mereka ambil adalah dengan menggunakan big data dan AI untuk mendongkrak penjualan dan kepuasan pelanggan. - Can big data give medical affairs an edge in strategic planning?
Salah satu bagian penting dari industri farmasi adalah medical affairs, yaitu team yang bertugas memberikan support terhadap aktivitas setelah sebuah obat disetujui dan diedarkan, baik terhadap pihak internal maupun eksternal (customer). Dengan semakin besarnya keterlibatan publik terhadap pengawasan dan penggunaan obat, maka peran medical affair menjadi semakin penting. Ketersediaan data yang melimpah menjadi sebuah tantangan dan peluang tersendiri. Bagaimana big data dapat membantu team medical affair dalam membuat perencanaan strategis? - Spark and S3 storage carry forward NBC big data initiative
NBC membuat inisiatif big data, dengan menggunakan Amazon S3 dan Spark. Keduanya dipakai untuk menggantikan HDFS dan MapReduce. Jeffrey Pinard, vice president data technology dan engineering di NBC, menjelaskan alasan di balik strategi tersebut.
Tutorial dan Pengetahuan Teknis
- Tensorflow Tutorial : Part 2 – Getting Started
Melanjutkan bagian 1 pekan lalu, tutorial Tensorflow bagian 2 ini menjelaskan mengenai instalasi Tensorflow dan sebuah contoh use case sederhana. - 30 Essential Data Science, Machine Learning & Deep Learning Cheat Sheets
Sekumpulan ‘cheat sheet atau referensi singkat yang sangat bermanfaat mengenai data science, machine learning dan deep learning, dalam python, R dan SQL. - A Solution to Missing Data: Imputation Using R
Salah satu permasalahan dalam pemanfaatan data untuk machine learning maupun analisis adalah missing data. Data yang tidak lengkap dapat mengacaukan model, sedangkan penanganan missing data terutama untuk data yang besar adalah sebuah momok tersendiri bagi data analis. Artikel ini mengulas mengenai permasalahan ini dan bagaimana mengatasinya dengan menggunakan R. - Apache Flink vs. Apache Spark
Apache flink dan Apache Spark termasuk framework yang paling banyak diminati dan diadopsi saat ini. Apa perbedaan di antara keduanya, dan apa kelebihan dan kekurangan masing-masing? - Featurizing images: the shallow end of deep learning
Melakukan training terhadap model deep learning dari nol memerlukan data set dan sumber daya komputasi yang yang besar. Dengan memanfaatkan model yang sudah ditraining (pre-trained) memudahkan kita dalam membangun classifier menggunakan pendekatan standar mashine learning.
Artikel ini menyajikan sebuah contoh kasus pemanfaatan pre-trained deep learning image classifier dari Microsoft R server 9.1 untuk menghasilkan fitur yang akan digunakan dengan pendekatan machine learning untuk menyelesaikan permasalahan yang belum pernah dilatihkan ke dalam model sebelumnya.
Pendekatan ini memudahkan pembuatan custom classifier untuk tujuan spesifik dengan menggunakan training set yang relatif kecil.
Rilis Produk
- Apache Solr 7.0.0 released
Apache Solr, platform pencarian noSQL yang populer, merilis versi 7.0.0 minggu ini. Rilis 7 ini mencakup 40 upgrade dari solr 6, 51 fitur baru, 56 bug fixes dan puluhan perubahan lainnya. - Apache Arrow 0.7.0
Mencakup 133 JIRA, fitur-fitur baru dan bug fixes untuk berbagai bahasa pemrograman. - Apache PredictionIO 0.12.0-incubating Release
Apache PredictionIO, sebuah server machine learning open source yang dibangun di atas open source stack, merilis versi 0.12.0. - R 3.4.2 Released
Rilis ini mencakup perbaikan terhadap minor bugs dan peningkatan performance. Seperti rilis minor sebelumnya, rilis ini kompatibel dengan rilis sebelumnya dalam seri R 3.4.x.
Contributor :
Tim idbigdata
always connect to collaborate every innovation 🙂
always connect to collaborate every innovation 🙂