Apa itu schema?
Bagi pengguna Microsoft Office Excel tentu tidak asing dengan capture tampilan di bawah ini:

Untuk mendapatkan informasi yang tepat dari capture diatas, tentunya diperlukan jawaban dari
beberapa pertanyaan berikut:
- Berapakah jumlah item informasi dari capture di atas?
- Apakah yang dijelaskan oleh masing-masing item informasi yang ada?
- Apakah kita dapat melakukan formulasi perhitungan dari item informasi yang ada?
Pertanyaan poin.1 dapat dijelaskan dengan capture berikut:

Jumlah kolom pada Excel menjelaskan jumlah item informasi yaitu terdapat 5 Item informasi yang
terdapat pada kolom "A","B","C","D","E".
Pertanyaan poin.2 dapat dijelaskan dengan capture berikut:

Informasi nama kolom "A","B","C","D","E" tidak cukup menjelaskan konten informasi yang ada,
sehingga diperlukan header/title yaitu: "Nama", "Jenis Kelamin", "Tempat Lahir", "Tanggal Lahir" dan
"Umur".
Pertanyaan poin.3 dapat dijelaskan dengan capture berikut:
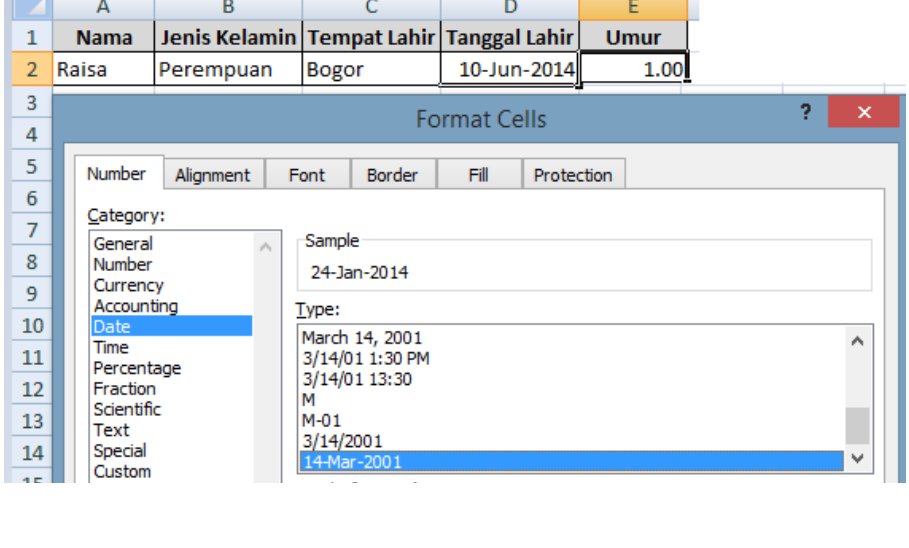
Kolom "D" dikategorikan sebagai tipe data "DATE" dan kolom "E" dikategorikan sebagai tipe data
"NUMBER". Nilai pada kolom "E" diperoleh dari perhitungan/calculation yang mungkin dilakukan
pada kolom dengan Tipe Data "NUMBER".
Poin-poin pertanyaan dan jawaban diatas sudah menjelaskan apa itu "schema" yang dapat
digunakan untuk mempermudah dalam mengakses dan mengolah informasi.
Schema pada RDBMS
SQL syntax sering digunakan untuk mengakses data-data yang ada di RDBMS (Database),
sehingga untuk dapat mengakses data harus dilakuan proses loading data ke Database terlebih
dahulu.
RDBMS bekerja dengan mekanisme "schema on write", sehingga pada saat proses loading data
juga dilakukan validasi data source untuk memastikan agar data yang tersimpan di database
memenuhi kriteria "schema" yang didefinisikan.
Berikut adalah contoh syntax create table pada RDBMS:
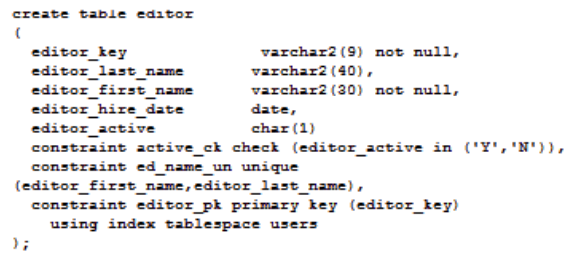
Pada perintah create table tersebut terdapat beberapa bagian yang merupakan "schema" untuk
memastikan agar data yang tersimpan pada table tersebut memenuhi kriteria/batasan sebagai
berikut:
- Nilai pada kolom "editor_key" tidak boleh kosong: not null
- Nilai pada kolom "editor_hire_date" harus merupakan informasi dengan format tanggal yang benar: date
- Nilai pada kolom "active_ck" hanya boleh memiliki salah satu dari dua nilai "Y" atau "N": check
- Nilai pada kolom "ed_name_un" tidak boleh ada yang sama: unique
Data yg sukses masuk ke database RDBMS hanyalah yang memenuhi kriteria "schema" yang di
definisikan, data yg tdk sesuai akan ter-reject.
Tentunya RDBMS harus mengalokasikan resource tersendiri untuk menjalankan Proses validasi
berdasarkan definisi "schema" pada saat loading data, hal ini menjadi tantangan tersendiri apabila
data yang akan di loading dalam ukuran yang sangat besar.
RDBMS memiliki kendali sepenuhnya terhadap data yg diload ke database, sehingga untuk
kebutuhan sharing data perlu dilakukan proses extract data kembali ke bentuk flatfile terlebih dahulu
yang juga memerlukan alokasi resource tersendiri.
Schema pada HIVE
Akses data yang tersimpan pada environtment HADOOP (HDFS) menggunakan SQL-Like syntax
dimungkinkan dengan menggunakan HIVE.
Hive bekerja dengan mekanisme "schema on read", sehingga proses upload data ke HDFS
menggunakan hive tidak melalui proses validasi untuk memenuhi kriteria "schema" yang di
definisikan:
Contoh perintah create table di HIVE yang berfungsi sebagai "schema":
CREATE TABLE siswa
(
nama STRING,
jenis_kelamin STRING,
tempat_lahir STRING,
tanggal_lahir TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|';
Pada contoh perintah create table diatas saya akan menggunakan kolom
tanggal_lahir yang memiliki tipe data TIMESTAMP dalam menjelaskan
penggunaan "
schema" pada
HIVE.
Bagian berikut memperlihatkan content dari file siswa.dat yang nantinya akan diakses
melalui table siswa.
hive> ! head /home/impala-dev/siswa.dat;
Raisa|Perempuan|Bogor| 2005-13-01 00:00:00.0
Rafi|Laki-laki|Bekasi|2003-03-04 00:00:00.0
Rifqi|Laki-laki|Bogor|2008-11-06 00:00:00.0
Delimiter yang digunakan untuk memisahkan kolom pada content file siswa.dat adalah karakter "|", pada baris pertama kolom ke-4 sengaja digunakan data tanggal dengan informasi bulan ke-13 untuk keperluan testing.
File siswa.dat merupakan OS File yang akan diupload ke HDFS menggunakan HIVE.
Setelah table siswa ter-create, maka dilakukan upload data ke HDFS dari file siswa.dat sekaligus agar dapat diakses melalui table siswa.
hive> LOAD DATA LOCAL INPATH '/home/impala-dev/siswa.dat' INTO TABLE siswa;
Copying data from file:/home/impala-dev/siswa.dat
Copying file: file:/home/impala-dev/siswa.dat
Loading data to table lab1.siswa
Table lab1.siswa stats: [numFiles=1, numRows=0, totalSize=99, rawDataSize=0]
OK
Time taken: 0.937 seconds
Bagian berikut memperlihatkan bahwa content dari file siswa.dat sudah berhasil terupload di HDFS.
hive> ! hadoop dfs -cat /user/impala-dev/lab1/siswa/siswa.dat;
Raisa|Perempuan|Bogor|2005-13-01 00:00:00.0
Rafi|Laki-laki|Bekasi|2003-03-04 00:00:00.0
Rifqi|Laki-laki|Bogor|2008-11-06 00:00:00.0
Terlihat pada content data baris pertama bahwa meskipun nilai kolom ke-4 berupa karakter dengan nilai bulan ke-13 yang tidak memenuhi kriteria definisi kolom tanggal_lahir yang memiliki tipe TIMESTAMP pada table siswa, namun data tetap sukses terupload ke HDFS.
Bagian berikut memperlihatkan bahwa content dari file siswa.dat yang sudah berhasil ter-upload di HDFS dapat diakses menggunakan SQL-like Syntax.
hive> select * from siswa;
Raisa Perempuan Bogor NULL
Rafi Laki-laki Bekasi 2003-03-04 00:00:00
Rifqi Laki-laki Bogor 2008-11-06 00:00:00
Time taken: 0.324 seconds, Fetched: 3 row(s)
Terlihat pada baris pertama kolom ke-4 nilai "2005-13-01 00:00:00.0" tidak muncul dan digantikan dengan NULL, hal ini menjelaskan bahwa Hive bekerja dengan mekanisme "schema on read" yaitu pada saat syntax SQL-Like dijalankan HIVE melakukan validasi untuk memastikan nilai kolom yang di query harus memenuhi kriteria pada definisi "schema" (type data pada kolom tanggal_lahir yang memiliki tipe TIMESTAMP pada table siswa).
Berbeda dengan RDBMS yang memungkinkan dilakukannya validasi yang komplek pada saat loading data ke database (schema on write), hive tidak melakukan validasi yang komplek pada saat menjalakan syntax SQL (schema on read).
Mapreduce code dengan logic yang komplek untuk kebutuhan pre-process agar diperoleh output yang memenuhi kriteria definisi "schema" dapat dibuat menggunakan Tools HGrid247 yang berbasis GUI dengan design Flow Process melalui Drag & Drop.
Contributor :
Imam Turmudi
Seorang Project Manager yang gemar bersepeda lulusan Universitas Diponegoro. Pertama kali mengenal Database Tools pada saat dibangku SMA, yaitu produk DBASE III PLUS. Pernah mengenyam pengalaman membuat aplikasi menggunakan bahasa Assembler untuk microprocessor x86 dan microcontroller MCS-51. Setelah terjun ke dunia kerja cukup intens berinteraksi dengan produk RDBMS menggunakan SQL & PL-SQL. Saat ini sedang tertarik untuk mengimplementasikan pengalaman yang diperoleh
di area RDBMS untuk solusi Big Data.













