Apa itu Genomics?
Genomics adalah bidang yang mempelajari genome, untuk memahami bagaimana suatu organisme bekerja, dan apa akibat dari interaksi antar gen serta pengaruh lingkungan terhadapnya. Sedangkan genome adalah materi genetik yang menjadi cetak biru atau rancangan dari suatu mahluk hidup. Informasi ini diwariskan secara turun temurun dan tersimpan dalam DNA, atau pada beberapa jenis virus, dalam RNA.
Ukuran genome dinyatakan dalam bp atau base pair, yaitu jumlah pasangan nukleotida dalam DNA.
Manusia memiliki sekitar 3 miliar bp dalam genome-nya. Sebetulnya manusia genome manusia 99.9% mirip. Namun perbedaan yang hanya 0.1% tersebut telah menghasilkan keragaman yang sangat besar pada penampilan maupun kondisi fisik seseorang.
Apa Pentingnya Genomics?
Saat ini genomics memiliki peran yang besar dalam berbagai bidang, mulai dari kesehatan, pertanian, lingkungan, industri maupun perkembangan ilmu pengetahuan. Dengan mempelajari gen, manusia dapat menemukan solusi dari banyak permasalahan mendasar di banyak bidang kehidupan.
Misalnya, di bidang medis, genomics dapat membantu dalam meningkatkan kualitas diagnosis penyakit, mengidentifikasi predisposisi terhadap penyakit tertentu (misalnya diabetes tipe 2, penyakit huntington, dll), mendeteksi virus dan bakteri penyebab penyakit, mengembangkan obat yang disesuaikan dengan informasi genetik seseorang (disebut juga ‘personalized medicine’, misalnya penggunaan penanda genetik untuk membantu menentukan dosis War¬farin, obat anti penggumapalan darah, menentukan jenis dan dosis obat untuk kanker, dll), atau memantau pengaruh gaya hidup dan lingkungan terhadap genome dan kesehatan manusia.
Di bidang lingkungan, genomics membantu untuk menemukan sumber-sumber energi yang lebih sustainable seperti biofuels, mengendalikan polusi, melakukan dekontaminasi daerah yang terkena limbah (disebut juga bioremediation, seperti misalnya mikroba yang digunakan untuk membantu membersihkan tumpahan minyak di teluk Meksiko), memantau keragaman hayati dan identifikasi spesies baru.
Dalam bidang pertanian genomics dapat digunakan untuk mengembangkan tanaman yang lebih tahan terhadap serangan hama, penyakit, dan lingkungan, dapat juga digunakan untuk membantu mengidentifikasi hama, mengembangkan tanaman pangan yang lebih kaya kandungan gizi, ataupun mengembangkan ternak yang lebih berkualitas dan tahan terhadap serangan penyakit, dan lain sebagainya.
Teknologi di Balik Perkembangan Genomics
Peran genomics yang besar tersebut dimungkinkan dengan berkembangnya teknologi dalam bidang pemetaan gen dan pengolahan data.
Next Generation Sequencing
Dengan hadirnya teknologi yang disebut dengan Next Generation Sequencing, maka biaya untuk melakukan pemetaan genetik juga mengalami penurunan yang sangat ekstrim.
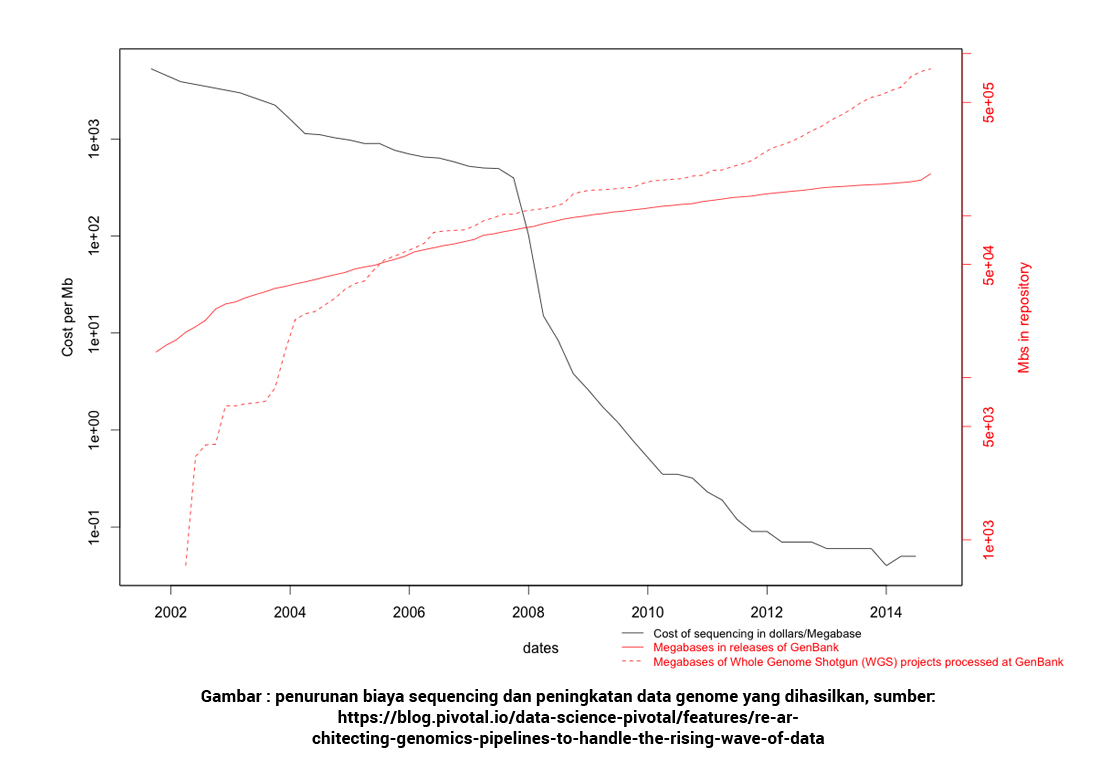
Jika sebelumnya biaya untuk melakukan sequencing atau pemetaan terhadap genome manusia adalah sebesar 100 juta US$ (dana yang digunakan pada Human Genome Project, yang di-launch di tahun 1986 dan selesai pada 2003), maka saat ini biaya pemetaan genome manusia adalah sekitar 1000 US$.
Penurunan biaya dan waktu pemrosesan menjadikan pemetaan genome menjadi sebuah proses yang terjangkau, sehingga banyak pihak dapat turut memanfaatkan dan mengembangkannya. Sebagai akibatnya, genomics pun menjadi sebuah bidang yang mengalami perkembangan yang sangat cepat pada dekade terakhir ini.
Big Data
Pemetaan dan analisis genome menghasilkan dan membutuhkan data yang sangat besar. Data hasil sequencing dapat mencapai 130 GB lebih per genome. Dengan semakin banyaknya genome yang dipetakan dan dianalisis, terjadilah ledakan di sisi data yang dihasilkan.
Tantangan selanjutnya adalah bagaimana data yang sedemikian besar dapat diproses dan dianalisis, sehingga semakin banyak penelitian maupun pemanfaatan data genomics dapat dilakukan.
Salah satu pendekatannya adalah dengan cara meningkatkan kecepatan prosesor. Teknologi seperti GPU ataupun FPGA (Field Programmable Gate Arrays) menjadi beberapa alternatif dalam hal ini. Solusi lain adalah penggunaan cloud computing, di mana data yang akan digunakan diproses di cloud, sehingga para peneliti tidak perlu membangun sendiri infrastruktur yang mereka gunakan. Namun permasalahannya adalah ketika diperlukan analisis seperti variant calling untuk mendeteksi mutasi gen, sejumlah data yang sangat besar perlu diakses dan dipindahkan ke environment analisis yang sesuai. Transfer data yang sangat besar melalui jaringan menjadi sebuah permasalahan berikutnya.
Dengan kehadiran big data, khususnya
Hadoop sebagai solusi komputasi dan penyimpanan data terdistribusi, para peneliti memiliki alternatif baru yang lebih terjangkau.
Hadoop menjadi alternatif bagi penyimpanan dan pemrosesan data genome dengan memberikan solusi berupa : biaya yang lebih terjangkau dengan pemanfaatan commodity hardware, peningkatan kapasitas komputasi dengan penggunaan banyak mesin secara paralel, mengurangi data movement dengan melakukan komputasi secara lokal, di mana data tersebut disimpan secara fisik.
Di samping itu, saat ini telah banyak teknologi yang dikembangkan di atas ataupun melengkapi Hadoop ekosistem, seperti misalnya Hive, Pig, Mahout, Yarn, dan lain sebagainya. Terlebih lagi setelah munculnya Spark sebagai platform pemrosesan in memory secara terdistribusi, big data menjadi sebuah alternatif solusi yang tidak dapat diabaikan lagi.
Salah satu pemanfaatan teknologi big data dalam bidang genomics ini adalah ADAM, yaitu platform analisis genomik dengan format file khusus. Dibangun menggunakan Apache
Avro, Apache
Spark dan Parquet. ADAM pada awalnya dikembangkan oleh Universitas Berkeley dan berlisensi Apache 2.
Referensi :
http://www.whygenomics.ca/why-should-i-care
http://blogs.uw.edu/ngopal/why-genomics/
https://blog.pivotal.io/data-science-pivotal/features/re-architecting-genomics-pipelines-to-handle-the-rising-wave-of-data
Contributor :
M. Urfah
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng.
Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun.
Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.