
Apache Arrow – in-memory columnar data layer

Pada tanggal 17 Februari 2016 lalu, Apache Software Foundation mengumumkan Apache Arrow sebagai top-level project tanpa melalui masa inkubasi yang panjang. Apache Arrow semula merupakan pengembangan dari Apache Drill, dibangun atas kolaborasi beberapa project open source unggulan lainnya dan bertujuan untuk menjadi standar de-facto bagi pemrosesan data in-memory yang tersusun secara columnar. Proyek-proyek Big Data yang telah bergabung dalam pengembangan Apache Arrow adalah Calcite, Cassandra, Drill, Hadoop, HBase, Impala, Kudu (incubating), Parquet, Phoenix, Spark, Storm, Pandas dan Ibis.
Apache Arrow bukan merupakan sebuah engine ataupun sistem penyimpanan. Ia adalah sebuah format dan algoritma untuk bekerja secara hirarkis, in-memory dan columnar serta mendukung sejumlah bahasa pemrograman yang dapat bekerja diatasnya.“Data dalam memori yang tersusun secara columnar memungkinkan sistem dan aplikasi memproses data pada kecepatan maksimum dari hardware” ujar Todd Lipcon, pendiri Apache Kudu dan anggota komite manajemen Apache Arrow Project.
Pada banyak proses pengolahan data, 70-80% siklus CPU dihabiskan untuk proses serialisasi dan deserialisasi data antar proses. Arrow mengatasi masalah ini dengan memungkinkan adanya sharing data antar sistem dan proses tanpa melalui proses serialisasi, deserialisasi atau penggandaan memory. Penggunaan Apache Arrow diklaim mampu mempercepat proses hingga 100 kali.
![]()
![]()
Contributor :

Seorang pengembara dunia maya, sangat suka mengeksplorasi dan menelusuri tautan demi tautan dalam internet untuk memperoleh hal-hal menarik. Saat ini sedang berusaha mengasah ilmu googling. Memiliki kegemaran memancing walaupun saat ini lebih sering memancing di kantor, terutama memancing emosi.

Big Data sebagai alat bantu Pengeboran Minyak dan Gas

Industri minyak dan gas kini tengah menghadapi tantangan berat, seperti meningkatnya biaya produksi dan gejolak politik internasional. Hal tersebut mempersulit usaha ekplorasi dan pengeboran cadangan minyak baru.
Beberapa tahun belakangan ini Royal Dutch Shell mengembangkan ide untuk membangun ladang minyak yang didukung oleh data atau disebut “data-driven oilfield” dalam usaha untuk mengurangi biaya pengeboran yang merupakan biaya utama industri migas.Sejak beberapa tahun ini Shell sudah mulai memasang kabel serat optik dalam sumur minyak. Pada kabel serat optik ini terpasang sensor-sensor yang mengukur segala sesuatu dalam sumur. Dengan data-data dari sensor tersebut, Shell dapat melakukan analisa yang lebih akurat mengenai keadaan sumur minyak atau seberapa besar gas yang masih tersisa.
Sensor super sensitif dalam kabel serat optik membantu Shell menemukan minyak tambahan di dalam sumur yang diduga telah kering. Sensor-sensor yang buat oleh Hewlett-Packard ini menghasilkan data dalam jumlah yang sangat besar dan ditransfer ke dalam sistem komputasi awan Amazon Virtual Private Cloud dengan menggunakan Hadoop. Sejak pertama kali dimulai mereka telah mengumpulkan 46 petabyte data dan pada tes pertama yang mereka lakukan di salah satu sumur minyak menghasilkan 1 petabyte informasi.Shell juga bekerja sama dengan IBM dan DreamWorks Hollywood untuk memvisualisasikan data-data yang didapat oleh sensor. Semua data yang diterima dari sensor seismik dianalisis oleh sistem kecerdasan buatan yang dikembangkan oleh Shell dan dirender menjadi peta 3D dan 4D dari reservoir minyak. Meskipun analisis dilakukan dalam komputasi awan, visualisasi segera tersedia bagi awak yang bekerja di pabrik lokal.
Melihat hasil yang dicapai mereka berkeinginan memasang sensor untuk sekitar 10.000 sumur minyak, dengan perkiraan 10 Exabytes data, atau sekitar 10 hari dari semua data yang dihasilkan oleh internet.Sumber :
https://datafloq.com/read/shell-drills-deep-with-big-data/508 http://www.smartdatacollective.com/bernardmarr/358203/big-data-big-oil-amazing-ways-shell-uses-analytics-drive-business-success/508Contributor :

always connect to collaborate every innovation 🙂

Big Data dan Hidroponik

Big data dan hidroponik, mungkin terdengar seperti perpaduan yang kurang cocok. Memang tidak dapat dipungkiri bahwa pengaruh big data sudah demikian meluas, tak terkecuali pada sektor yang agak spesifik seperti hidroponik. Sistem otomasi pada pertanian dengan menggunakan teknik hidroponik tengah berkembang dengan pesat di dunia, dari Jepang, Cina, Inggris dan Uni Eropa serta Amerika Serikat.
Manfaat Bercocok Tanam Dengan HidroponikTeknik hidroponik dianggap sebagai suatu teknik produksi pangan yang sangat efisien saat ini. Banyak keunggulan dari teknik ini, misalnya penggunaan lahan yang lebih sedikit dan produksi pangan lebih banyak. Air yang digunakan pun dapat diolah dan dimanfaatkan kembali. Biaya pengangkutan dapat ditekan karena teknik ini sangat cocok diimplementasikan di wilayah perkotaan dengan jumlah populasi yang tinggi.
Bagaimana Big Data dan otomasi bekerja dengan hidroponikDi Jepang, Fujitsu telah mengembangkan sebuah layanan komputasi awan (cloud platform services) dengan nama Akisai. Sistem yang diluncurkan pada tahun 2012 ini menganalisa data-data yang didapatkan dari berbagai sensor yg di tempatkan di sekitar rumah kaca (greenhouse). Dengan informasi ini, seluruh perangkat pendukung seperti kipas ventilasi udara, mesin pemanas, dan sistem pengairan dikontrol secara otomatis. Melalui big data cloud service, sistem ini mampu mengumpulkan banyak data yang dapat dianalisa untuk menghasilkan kualitas pangan yang lebih baik.
Di Amerika Serikat ada Freight Farms, sebuah perusahaan yang membuat sistem pertanian hidroponik menggunakan kontainer bekas dengan menerapkan teknologi dan otomasi pertanian. Mereka mengumpulkan data dari berbagai komponen utama pertanian seperti udara, air, suhu dan pertumbuhan tanaman untuk mengelola dan memonitor pertanian.Dengan data yang dikumpulkan tersebut mereka membuat sebuah program custom elearning development, sehingga para penggunanya dapat mempelajari cara terbaik untuk bercocok tanam dengan Freight Farms. Menurut Brad McNamara, co founder dari Freight Farms, melalui sistem elearning yang dibangun ini, orang yg saat ini bergabung dengan Freight Farms akan memiliki pengetahuan yang jauh lebih baik, karena telah mendapatkan pengetahuan dari data yang dikumpulkan dari pengguna-pengguna sebelumnya. Dengan jaringan yang terdiri dari para petani Freight Farms, mereka mendapatkan banyak informasi yang dapat diterapkan.
Demikian juga di Cina, Alesca, sebuah startup yang mengubah kontainer bekas menjadi sebuah solusi jaringan pertanian hidroponik yang menggunakan sistem otomatisasi open-source dan analisa big data. Alesca mendesain dan membangun sistem pertanian multi-format dan menggabungkannya dengan penginderaan cerdas (smart sensing) dan aplikasi yang terhubung komputasi awan. Sistem connected farm ini menjadikan jaringan pertanian Alseca sebagai sebuah jaringan produksi pangan kota yang terdistribusi (city distributed food production system).Penggunaan kontainer sebagai area tanam memungkinkan untuk membuat microclimate atau kondisi lingkungan yang paling ideal untuk berbagai jenis tanaman yang ditanam. Hasil tersebut dicapai dengan menggunakan sistem otomasi canggih, penyinaran menggunakan LED yang optimal dan komponen software terkini untuk membangun lingkungan yang ideal untuk masing-masing jenis tanaman. Tanaman dipantau oleh sensor yang melaporkan mengenai kesehatan, pertumbuhan, dan kecukupan nutrisi serta keseluruhan informasi mengenai lingkungan yang membutuhkan penyesuaian untuk mencapai kondisi pertumbuhan yang paling ideal. Alesca yakin bahwa ini merupakan trend masa depan untuk produksi pangan lokal berskala besar di kota-kota padat yang disebut local concept zero-mile food.
Masalah Yang Datang dengan Otomasi PertanianHambatan terbesar untuk keberhasilan jenis otomasi produksi pangan ini adalah dari segi biaya produksi pangan hidroponik. Peningkatan skala produksi dan tuntutan untuk menjaga efektifitas dan nilai ekonomis mengingatkan kita pada tantangan yang dihadapi di masa sebelumnya. Jika sebelumnya hambatan yang dihadapi adalah dari besarnya jumlah tenaga kerja yang dibutuhkan, maka tantangan saat ini adalah pada kebutuhan listrik yang besar, dan pengeluaran untuk sistem pemupukan, pendingin, pemanas, dan pencahayaan yang tidak sedikit.
Namun demikian, berkat adanya software baru dan otomasi pada kebun hidroponik, banyak perubahan yang terjadi pada teknik bercocok tanam yang memungkinkan untuk dikembangkan dalam skala industri dan komersil, sehingga cukup kompetitif dalam mendukung ketersediaan pangan dunia.
Referensi :
http://www.fujitsu.com/global/about/resources/news/press-releases/2012/0718-01.htmlhttp://www.npr.org/sections/thesalt/2015/02/23/388467327/-freight-farms-grow-local-flavor-year-round
http://technode.com/2015/11/03/alesca-life-introduces-farming-service-model-indoor-farming/ Contributor :always connect to collaborate every innovation 🙂

Instalasi Hadoop Cluster di Ubuntu 14.04 VMWare [Bagian 2]

Berikut ini adalah langkah berikutnya dari instalasi Hadoop Cluster di Ubuntu 14.04 VMWare. Untuk langkah sebelumnya bisa dilihat di Bagian 1.
9. Duplikasi Ubuntu InstanceUntuk membuat 3 instance server ubuntu, shutdown VMWare, dan kopi direktori tempat file-file VM Image tersebut dua kali. Untuk mengetahui letak direktori, buka menu Player → Manage → Virtual Machine Setting di bagian Working Directory
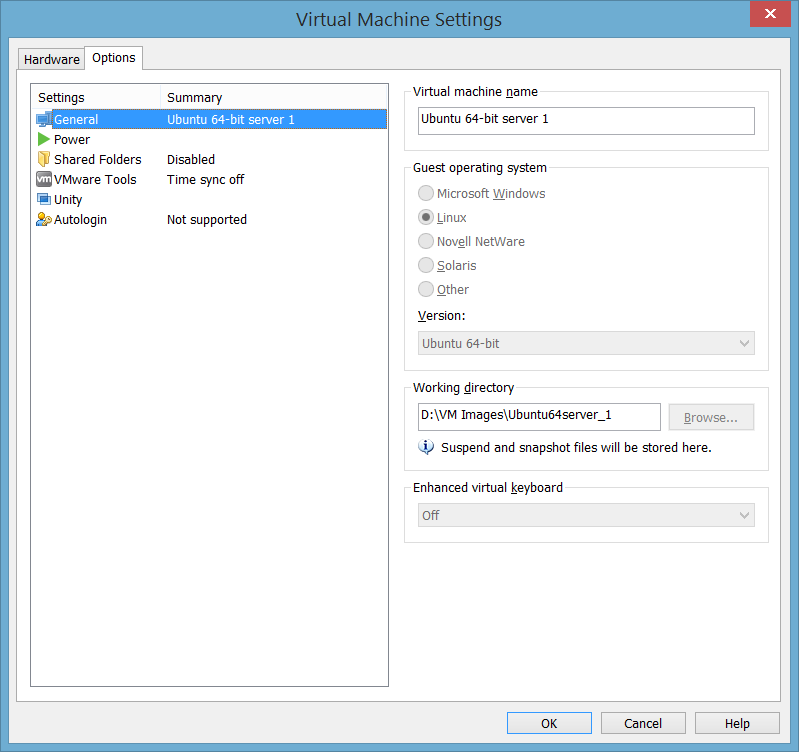
re, dan kopi direktori tempat file-file VM Image tersebut dua kali. Untuk mengetahui letak direktori, buka menu Player → Manage → Virtual Machine Setting di bagian Working Directory
Selanjutnya, jalankan VMWare Player, pilih menu Open a Virtual Machine. Buka file .vmx di ke 2 direktori hasil copy tersebut, dan pilih Play virtual Machine. Anda akan mendapatkan dialog box
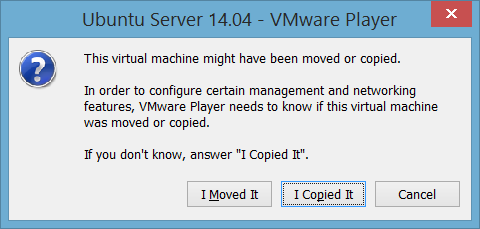
10. Setting koneksi
Ada beberapa hal yang perlu dilakukan, yaitu setting hostname di file /etc/hostname, setting mapping hostname di file /etc/hosts, dan setting ssh connection.Setting hostname
Buka 3 Virtual machine tersebut, ubah nama masing-masing menjadi ubuntu1, ubuntu2 dan ubuntu 3, dengan cara edit file /etc/hostname :
hduser@ubuntu:~$ sudo vi /etc/hostnameMisalnya untuk server ubuntu3 menjadi sbb:

Edit file /etc/hosts di ke 3 server sbb:
Server 1 : ubuntu1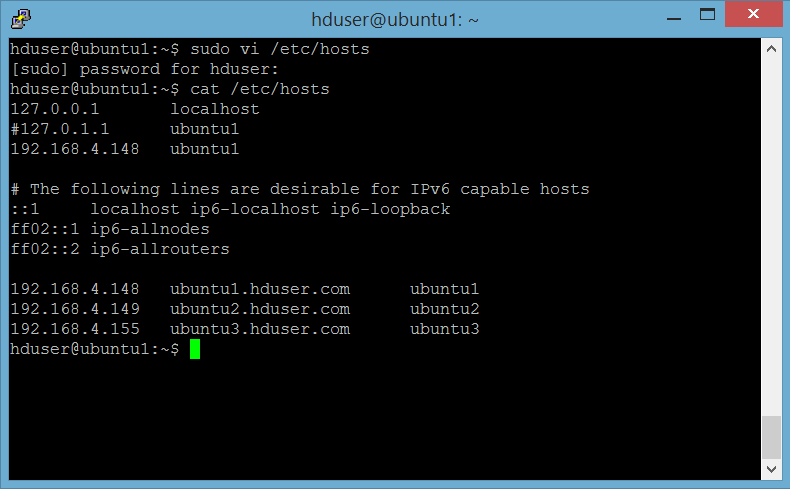
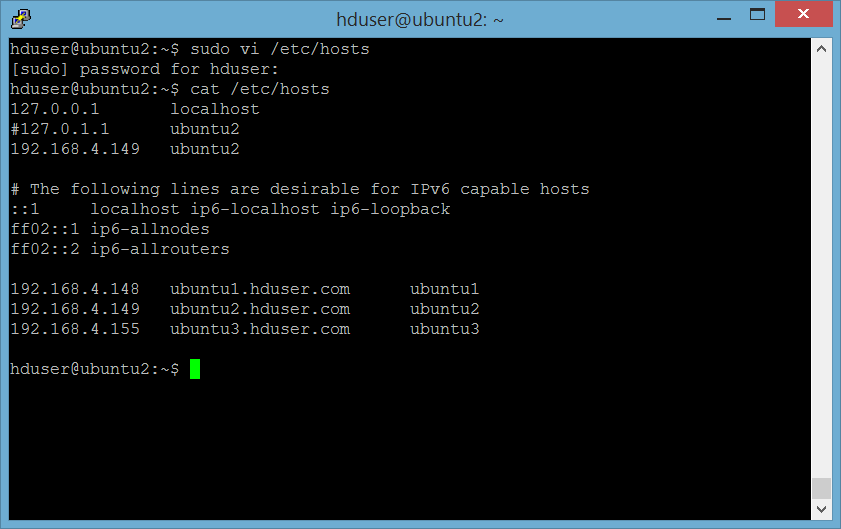
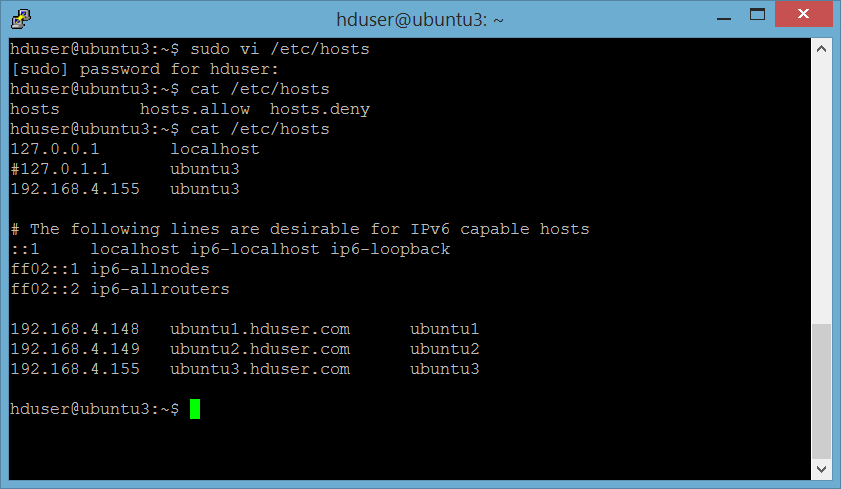

Lakukan di ke 3 server.
Setting sshDi server ubuntu1, lakukan:
hduser@ubuntu1:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu2hduser@ubuntu1:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu3
Untuk mengetes koneksi, lakukan :
hduser@ubuntu1:~$ ssh hduser@ubuntu2hduser@ubuntu1:~$ ssh hduser@ubuntu2
Seharusnya sudah tidak diminta password untuk ssh tersebut.
Di server ubuntu2 dan ubuntu3, lakukan:hduser@ubuntu2:~$ ssh-copy-id -i /home/hduser/.ssh/id_rsa.pub hduser@ubuntu1
Untuk mengetes koneksi, lakukan :
hduser@ubuntu2:~$ ssh hduser@ubuntu1Seharusnya sudah tidak diminta password untuk ssh tersebut.
11. Format HDFS file systemLakukan ini di namenode (server ubuntu1) pada pertama kali instalasi. Jangan melakukan namenode format untuk Hadoop yang sudah berjalan (berisi data), karena perintah format ini akan menghapus semua data di HDFS, dan kemungkinan akan membuat hdfs dalam cluster anda tidak konsisten satu sama lain (namenode dan data node).
hduser@ubuntu1:$ hdfs namenode -formatOutputnya akan seperti berikut ini:
|
hduser@ubuntu1:$ /usr/local/hadoop/bin/hadoop namenode -format
10/05/08 16:59:56 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = ubuntu/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010 ************************************************************/ 10/05/08 16:59:56 INFO namenode.FSNamesystem: fsOwner=hadoop,hadoop 10/05/08 16:59:56 INFO namenode.FSNamesystem: supergroup=supergroup 10/05/08 16:59:56 INFO namenode.FSNamesystem: isPermissionEnabled=true 10/05/08 16:59:56 INFO common.Storage: Image file of size 96 saved in 0 seconds. 10/05/08 16:59:57 INFO common.Storage: Storage directory .../hadoop-hadoop/dfs/name has been successfully formatted. 10/05/08 16:59:57 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1 ************************************************************/ hduser@ubuntu1:$ |
12. Start HDFS dan Yarn
Lakukan ini di namenode (server ubuntu1).Start hdfs :
hduser@ubuntu1:$ /usr/local/hadoop/sbin/start-dfs.sh
hduser@ubuntu1:$ /usr/local/hadoop/sbin/start-yarn.sh

Untuk memastikan data node sudah berjalan dengan baik, di data node server (ubuntu2 dan ubuntu3), cek log di /usr/local/hadoop/logs/hadoop-hduser-datanode-ubuntu2.log dan /usr/local/hadoop/logs/hadoop-hduser-datanode-ubuntu3.log
ika anda mendapatkan message seperti berikut ini:2015-11-10 12:35:53,154 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: ubuntu1/192.168.4.148:54310
Maka pastikan bahwa setting /etc/hosts di ke 3 server sudah dilakukan dengan benar seperti di poin 10 di atas (Setting Koneksi). Cek ip masing-masing server dengan perintah ifconfig. Cek service di masing-masing server dengan perintah jps.
12. Test HDFSUntuk memastikan semua node sudah naik dan berfungsi dengan baik, kita akan meng-upload file test ke dfs. Lakukan perintah berikut ini di server name node (ubuntu1):
buat direktori /data di hdfshadoop fs -mkdir /data
upload file /usr/local/hadoop/README.txthadoop fs -put /usr/local/hadoop/README.txt /data/README.txt

13. Hadoop Web Interface
Anda dapat mengakses hadoop web interface dari browser anda, dengan mengakses namenode:50070. Akan tampil halaman seperti berikut ini.
Dari keterangan di atas terlihat bahwa terdapat 2 data nodes yang hidup dan terhubung. Klik menu Datanodes untuk melihat informasi lebih detail mengenai kedua data node tersebut:

File yang kita buat tadi akan terlihat di menu Utilities → Browse the file system

Demikianlah tutorial instalasi Hadoop kali ini, semoga bermanfaat.
Nantikan tutorial berikutnya 🙂
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.
Seri Tutorial : Instalasi Hadoop Cluster di Ubuntu 14.04 VMWare [Bagian 1]
Setelah pada tutorial lalu kita membahas mengenai instalasi Hadoop single node, kali ini kita akan membahas langkah instalasi Hadoop cluster di dalam VMWare.
Sebagai catatan, karena pada tutorial ini kita akan menjalankan 3 buah virtual machine secara bersamaan, maka PC atau laptop yang akan digunakan haruslah memiliki setidaknya 8 GB RAM, dan alokasi total untuk ke 3 VM ini sebaiknya tidak melebihi 4GB.
Berikut ini langkah instalasi Hadoop di Ubuntu 14.04 vmWare. Dalam tutorial ini digunakan hadoop 2.6.0. Untuk konfigurasi ini kita akan menggunakan 1 server namenode dan 2 server datanode. Yang akan kita lakukan adalah menginstall 1 mesin sampai selesai, lalu copy 2 kali untuk mendapatkan 3 instance server, dan kemudian kita setting agar ke-3 nya dapat berkomunikasi satu sama lain.
| IP | Type Node | Hostname |
|---|---|---|
| 192.168.4.148 | Name node | ubuntu1 |
| 192.168.4.149 | Data node 1 | ubuntu2 |
| 192.168.4.155 | Data node 2 | ubuntu3 |
1. Install VMWare Player
Install VMWare player, tergantung OS host anda, 32 atau 64 bit : https://my.vmware.com/web/vmware/free#desktop_end_user_computing/vmware_player/6_02. Install Ubuntu
Install Ubuntu 14.04 di VMWare player, anda. Download iso image Ubuntu 14.04 LTS di http://releases.ubuntu.com/14.04/ (sekali lagi, perhatikan keperluan anda, 32 atau 64 bit OS) Agar dapat berkomunikasi satu sama lain, termasuk dapat diakses melalui puTTY, set network setting ke Bridged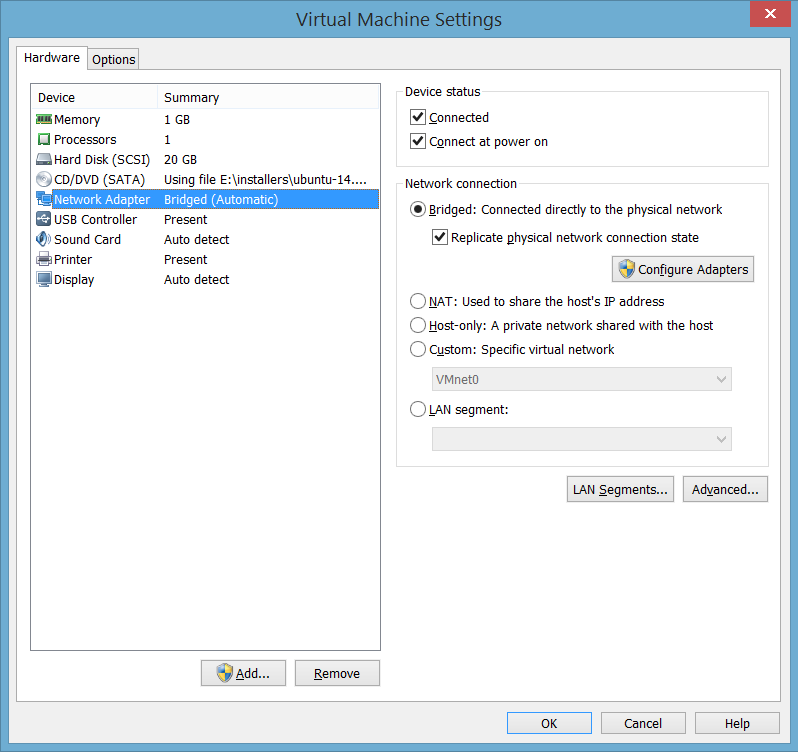
3. Install jdk
Ada beberapa pilihan yang bisa anda install, di antaranya openjdk atau oracle jdk. Untuk open jdk pilih setidaknya openjdk 7, dengan perintah sbb:
user@ubuntu:~$ sudo apt-get install openjdk-7-jdk |
Anda bisa juga menginstall jdk 7 oracle, dengan langkah sbb:
- download jdk 7 di http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html , sekali lagi, perhatikan kebutuhan anda 32 atau 64 bit
- upload ke ubuntu
- Extract package yang sudah diuplad tersebut
user@ubuntu:~$ tar xzvf jdk-7u79-linux-x64.tar.gz
- pindahkan ke direktori /usr/local/java
user@ubuntu:~$ sudo cp -Rh jdk1.7.0_79 /usr/local/java
5. Create dedicated group dan user untuk hadoop
Membuat user hduser dan group hdgroup untuk menjalankan hadoop. Langkah ini tidak harus dilakukan, tapi disarankan untuk memisahkan instalasi hadoop dengan aplikasi2 lain di mesin yang sama.
user@ubuntu:~$ sudo addgroup hdgroup user@ubuntu:~$ sudo adduser --ingroup hdgroup hduser |
user@ubuntu:~$ sudo adduser hduser sudo |
6. Setting jdk path Sebelumnya cek instalasi dengan perintah:
user@ubuntu:~$ java -version java version "1.7.0_79" Java(TM) SE Runtime Environment (build 1.7.0_79-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode) |
Login ke user hduser dengan perintah:
user@ubuntu:~$ su hduser |
Set JAVA_HOME di file .bashrc dengan memasukkan path yg sesuai, misalnya untuk java di direktori /usr/local/java , maka tambahkan baris berikut ini:
export JAVA_HOME=/usr/local/java
Apply setting dengan jalankan perintah berikut ini:
hduser@ubuntu:~$ . .bashrc |
7. Configure SSH
Hadoop memerlukan akses SSH untuk memanage node-node-nya. Kita perlu melakukan konfigurasi akses SSH ke localhost untuk user hadoop yang sudah kita buat sebelumnya, dan ke data node-nya nantinya.a. install ssh
hduser@ubuntu:~$ sudo apt-get install ssh |
b. generate an SSH key untuk user hadoop
hduser@ubuntu:~$ ssh-keygen -t rsa -P "" |
Perintah di atas akan membuat RSA key pair dengan password kosong. Sebenarnya penggunaan password kosong ini tidak disarankan dari sisi keamanan, namun dalam hal ini kita memerlukan akses tanpa password untuk keperluan interaksi Hadoop dengan node-node-nya. Tentunya kita tidak ingin memasukkan password setiap kali Hadoop mengakses node-nya, bukan?
c. enable akses SSH ke local machine dengan key yang baru dibuat
hduser@ubuntu:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys |
d. test setting SSH
Langkah terakhir adalah testing setup SSH tersebut dengan melakukan koneksi ke localhost menggunakan user hadoop. Langkah ini juga diperlukan untuk menyimpan host key dingerprint ke file known_host milik user hadoop.
hduser@ubuntu:~$ ssh localhost The authenticity of host 'localhost (::1)' can't be established. ECDSA key fingerprint is 34:72:32:43:11:87:fa:83:7e:ea:13:e6:43:68:28:0f. Are you sure you want to continue connecting (yes/no)? yes |
Langkah terakhir adalah testing setup SSH tersebut dengan melakukan koneksi ke localhost menggunakan user hadoop. Langkah ini juga diperlukan untuk menyimpan host key fingerprint ke file known_host milik user hadoop.
8. Instalasi Hadoop
Download hadoop di https://www.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz, extract ke sebuah direktori, misalnya /usr/local/hadoop.
hduser@ubuntu:~$ cd /usr/local hduser@ubuntu:~$ sudo tar xzf hadoop-2.6.0.tar.gz hduser@ubuntu:~$ sudo cp -Rh hadoop-2.6.0 /usr/local/hadoop |
Tambahkan baris berikut ini ke akhir file $HOME/.bashrc dari user hadoop. Jika anda menggunakan shell selain bash, maka anda perlu meng-update config file yang bersesuaian. Berikut ini setting untuk instalasi openjdk7:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END |
Untuk instalasi java di /usr/local/java, sesuaikan setting JAVA_HOME sbb:
export JAVA_HOME=/usr/local/javaCreate direktori untuk hadoop filesystem
Berikut ini beberapa direktori yang perlu dibuat untuk hadoop file system, yang akan di-set dalam parameter dfs.namenode.name.dir , dfs.datanode.name.dir di file
/usr/local/hadoop/etc/hadoop/conf/hdfs-site.xml dan parameter hadoop.tmp.dir di file /usr/local/hadoop/etc/hadoop/conf/core-site.xml: /app/hadoop/namenode, /app/hadoop/datanode dan /app/hadoop/tmp
hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/namenode hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/datanode hduser@ubuntu:~$ sudo chown hduser:hdgroup /app/hadoop/datanode hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/tmp hduser@ubuntu:~$ sudo chown hduser:hdgroup /app/hadoop/tmp |
Update Hadoop File Configuration
Berikut ini beberapa file yang perlu di-update di direktori /usr/local/hadoop/etc/hadoop/etc/hadoopa. File hadoop-env.sh
hduser@ubuntu:~$ vi $HADOOP_INSTALL/etc/hadoop/hadoop-env.sh |
b. File-file *-site.xml
Dalam file /usr/local/hadoop/etc/hadoop/core-site.xml:Dalam file /usr/local/hadoop/etc/hadoop/mapred-site.xml:
Dalam file /usr/local/hadoop/etc/hadoop/conf/hdfs-site.xml:
Lho, gitu aja? Oh tentu tidak..!
Langkah selanjutnya akan dijelaskan pada bagian 2, so stay tune 🙂
Contributor :Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.

Seri Tutorial : Instalasi Hadoop Single Node di Ubuntu 14.04 VMWare

Jika anda baru saja berkenalan dengan big data dan ingin mengetahui lebih dalam mengenai Hadoop, anda mungkin ingin mencoba melakukan instalasi Hadoop anda sendiri. Langkah yang paling sederhana adalah dengan melakukan instalasi Hadoop di satu mesin, atau disebut dengan single node. Jika anda tidak memiliki environment linux sendiri, maka yang paling mudah adalah menjalankan linux sebagai virtual machine, dengan VMWare atau VirtualBox misalnya.
Dengan melakukan instalasi dan setup sendiri, anda akan mendapatkan gambaran yang lebih jelas mengenai apa saja yang menjadi komponen Hadoop, dan bagaimana kira-kira Hadoop bekerja.
Dalam tutorial ini akan dijelaskan langkah instalasi Hadoop 2.6.0 di Ubuntu 14.04 VMware
1. Install VMWare Player
Install VMWare player, tergantung OS host anda (32 atau 64 bit) :https://my.vmware.com/web/vmware/free#desktop_end_user_computing/vmware_player/6_0
2. Install Ubuntu
Install Ubuntu 14.04 Download iso image Ubuntu 14.04 LTS di http://releases.ubuntu.com/14.04/ (tergantung keperluan anda, 32 atau 64 bit)3. Install openjdk
Install open jdk 7 dengan command sbb:
user@ubuntu:~$ sudo apt-get install openjdk-7-jdk |
|
java version "1.7.0_79"
OpenJDK Runtime Environment (IcedTea 2.5.6) (7u79-2.5.6-0ubuntu1.14.04.1) OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
5. Create dedicated user untuk hadoop
Membuat user hadoop untuk menjalankan hadoop. Langkah ini tidak harus dilakukan, tapi disarankan untuk memisahkan instalasi hadoop dengan aplikasi2 lain di mesin yang sama.
|
6. Masukkan hadoop ke dalam sudoers (untuk create direktori, set permission, dll)
user@ubuntu:~$ sudo adduser hduser sudo |
7. Configure SSH
Hadoop memerlukan akses SSH untuk memanage node-node-nya. Untuk single node Hadoop, kita perlu melakukan konfigurasi akses SSH ke localhost untuk user hadoop yang sudah kita buat sebelumnya.a. install ssh
user@ubuntu:~$ sudo apt-get install ssh |
b. generate an SSH key untuk user hadoop
|
Baris ke dua command di atas akan membuat RSA key pair dengan password kosong. Sebenarnya penggunaan password kosong ini tidak disarankan dari sisi keamanan, namun dalam hal ini kita memerlukan akses tanpa password untuk keperluan interaksi Hadoop dengan node-node-nya. Tentunya kita tidak ingin memasukkan password setiap kali Hadoop mengakses node-nya, bukan?
c. enable akses SSH ke local machine dengan key yang baru dibuat
hduser@ubuntu:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys |
d. test setting SSH
Langkah terakhir adalah testing setup SSH tersebut dengan melakukan koneksi ke localhost menggunakan user hadoop. Langkah ini juga diperlukan untuk menyimpan host key dingerprint ke file known_host milik user hadoop.
hduser@ubuntu:~$ ssh localhost |
8. Instalasi Hadoop
Download hadoop di https://www.apache.org/dist/hadoop/core/hadoop-1.2.1/hadoop-1.2.1.tar.gz, extract ke sebuah direktori, misalnya /usr/local/hadoop.
hduser@ubuntu:~$ cd /usr/local hduser@ubuntu:~$ sudo tar xzf hadoop-1.0.3.tar.gz hduser@ubuntu:~$ sudo mv hadoop-1.0.3 hadoop |
Jangan lupa take ownership dari direktori tersebut
|
|
9. Update File .bashrc
Tambahkan baris berikut ini ke akhir file $HOME/.bashrc dari user hadoop. Jika anda menggunakan shell selain bash, maka anda perlu meng-update config file yang bersesuaian
|
11. Update Hadoop File Configuration
Berikut ini beberapa file yang perlu diupdate di direktori /usr/local/hadoop/conf/
a. File hadoop-env.sh
hduser@ubuntu:~$ vi $HADOOP_INSTALL/conf |
b. File-file *-site.xml
Buat temporary direktori untuk hadoop app untuk parameter hadoop.tmp.dir, dalam hal ini digunakan /app/hadoop/tmp.
hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/tmp hduser@ubuntu:~$ sudo chown hduser:hdgroup /app/hadoop/tmp |
Catatan : jika langkah di atas terlewat, maka kemungkinan anda akan mendapatkan error permission denied atau java.io.IOException ketika anda akan memformat HDFS namenode.
Dalam file conf/core-site.xml:Dalam file conf/mapred-site.xml:
Dalam file conf/hdfs-site.xml:
12.Format HDFS file system
Lakukan pada pertama kali instalasi. Jangan melakukan namenode format untuk Hadoop yang sudah berjalan (berisi data), karena perintah format ini akan menghapus semua data di HDFS.
hduser@ubuntu:$ /usr/local/hadoop/bin/hadoop namenode -formatOutputnya akan seperti berikut ini:
|
13. Start single-node Hadoop cluster
hduser@ubuntu:~$ /usr/local/hadoop/sbin/start-dfs.sh
Perintah ini menjalankan Namenode, Datanode, Jobtracker dan Tasktracker Outputnya seperti di bawah ini:
|
hduser@ubuntuserver:~$ /usr/local/hadoop/sbin/start-dfs.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hduser-namenode-ubuntuserver.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hduser-datanode-ubuntuserver.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hduser-secondarynamenode-ubuntuserver.out |
Salah satu cara praktis mengecek Hadoop proses apa saja yang berhasil dijalankan adalah dengan perintah jps (termasuk di dalam package open jdk 6).
|
14. Stop Hadoop services
hduser@ubuntu:~$ /usr/local/hadoop/bin/stop-dfs.sh |
Outputnya seperti di bawah ini:
|
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.

Ledakan Data di Bidang Genomics

Salah satu bidang yang menghasilkan data yang sangat besar adalah genomics. Seiring dengan semakin terjangkaunya biaya pemetaan dan semakin banyak genome yang dianalisis, data genomics akan mengalami ledakan yang dahsyat. Bidang ini bahkan diperkirakan akan menjadi penghasil data terbesar, melebihi data astronomi misalnya.
Menurut laporan yang dipublikasikan di jurnal PloS Biology (http://dx.doi.org/10.1371/journal.pbio.1002195), di tahun 2025 akan ada antara 100 juta sampai 2 milyar human genome yang telah dipetakan. Kapasitas penyimpanan data untuk keperluan ini saja dapat mencapai 2–40 exabytes (1 exabyte = 1018 bytes), karena jumlah data yang harus disimpan untuk sebuah genome setidaknya memerlukan 30 kali ukuran data genome itu sendiri. Hal ini untuk mengantisipasi adanya kesalahan yang mungkin timbul selama proses pemetaan dan analisis pendahuluan.
Jumlah tersebut melebihi perkiraan kapasitas penyimpanan data YouTube di tahun 2025, yang sebesar 1-2 exabytes, dan data Twitter yang diperkirakan mencapai 1-17 petabytes per tahun (1 petabyte = 1015 bytes). Jumlah data tersebut juga melebihi perkiraan data tahunan Square Kilometre Array (http://www.nature.com/news/cloud-computing-beckons-scientists-1.15298), sebuah project yang direncanakan menjadi project astronomi terbesar di dunia.
Namun permasalahan penyimpanan ini hanyalah salah satu permasalahan saja. Keperluan komputasi untuk mengumpulkan, mendistribusi, dan menganalisis data genomics ini akan jauh lebih besar lagi.
Perubahan Besar
Gene Robinson, ahli biologi UIUC yang juga salah satu co-author paper tersebut menyatakan, hal ini menegaskan bahwa bidang genomics akan memberikan banyak tantangan berat. Beberapa perubahan besar perlu dilakukan untuk dapat menangani ukuran data yang besar dan kebutuhan akan kecepatan analisis.
Narayan Desai, seorang computer scientist dari Ericsson San Jose mengatakan bahwa perbandingan data dengan bidang lain seperti dilaporkan dalam paper tersebut sebenarnya kurang tepat. Ada banyak hal yang tidak diperhatikan dalam melakukan perbandingan, seperti misalnya laporan tersebut menganggap ringan pemrosesan dan analisis video dan teks yang dilakukan oleh YouTube maupun Twitter, seperti misalnya untuk keperluan iklan yang terarah maupun penyajian video ke dalam format yang beragam.
Meskipun demikian, genomics tetap harus memperhatikan permasalahan mendasar mengenai berapa besar data yang sebenarnya akan dihasilkan di bidang ini. Karena sehebat apapun teknologi, kapasitas penyimpanan dan komputasi untuk mengumpulkan dan menganalisis data tetaplah terbatas, sehingga kedua hal tersebut harus digunakan dengan sebaik-baiknya. Karena proses pemetaan semakin terjangkau, komunitas genomics pun tumbuh dengan sangat pesat dan tersebar. Komunitas yang tersebar ini cukup menyulitkan dalam mengatasi permasalahan seperti yang disebutkan di atas. Bidang-bidang lain yang memerlukan banyak resource semacam ini, sseperti misalnya high-energy physics, komunitasnya lebih terpusat. Mereka memerlukan koordinasi dan konsensus untuk perancangan instrumen, pengumpulan data, dan strategi sampling. Berbeda dengan data genomics yang terkotak-kotak, meskipun akhir-akhir ini mulai muncul ketertarikan untuk menyimpan data-data genomics secara terpusat dalam cloud.
Kerja Sama
Berbeda dengan ahli genomics, setelah data mentah dikumpulkan para astronomer dan ahli fisika segera memprosesnya, dan kemudian data mentah tersebut dibuang. Cara ini menyederhanakan langkah-langkah distribusi dan analisis selanjutnya. Akan tetapi genomics belum memiliki standar baku untuk konversi data mentah menjadi data yang sudah diproses.
Menurut paper tersebut, jenis analisis yang ingin dilakukan oleh para ahli biologi terhadap data genomics ini juga sangat beragam dan metode yang digunakan belum tentu dapat berfungsi baik dengan peningkatan volume data yang besar. Misalnya untuk membandingkan dua genome diperlukan perbandingan antara dua set varian genetik. “Jika kita mempunyai satu juta genome, maka jumlah perbandingannya adalah satu juta kuadrat”, papar Saurabh Sinha, seorang komputer saintis dari UIUC dan salah satu co-author dari paper tersebut. “Algoritma yang digunakan untuk melakukan proses tersebut akan sangat kewalahan.”
Robert Brunner, seorang Observational cosmologist dari UIUC mengatakan, alih-alih membandingkan bidang ilmu, dia ingin ada sebuah kerja sama dalam mengatasi permasalahan terkait big-data yang mencakup banyak bidang, sehingga didapatkan manfaat yang lebih besar. Misalnya keterbatasan jenjang karir untuk spesialisasi komputasi dalam dunia sains, dan kebutuhan akan jenis penyimpanan dan kapasitas analisis yang belum tentu dapat dipenuhi oleh dunia industri.
“Genomics menghadapi tantangan yang sama dengan astronomi, ilmu mengenai atmosfer, ilmu tentang tumbuh-tumbuhan, fisika partikel, dan domain-domain big data yang lain,” kata Brunner. “Yang penting untuk dilakukan saat ini adalah menentukan apa masalah yang dapat kita pecahkan bersama-sama.”
Diterjemahkan dari : Genome researchers raise alarm over big data
Contributor :Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.

Microsoft Machine Learning Toolkit Bergabung ke Open Source

Kurang dari seminggu setelah Google mengumumkan dibukanya status TensorFlow menjadi open source, Microsoft pun membuka akses ke machine learning platform mereka, DMTK (Distributed Machine Learning Toolkit).
DMTK dikembangkan oleh lab penelitian Microsoft Asia, dan di dalamnya mencakup server-based framework yang memungkinkan developer melakukan pemrograman machine learning dengan mudah. Toolkit ini juga mencakup dua algoritma yang dikembangkan Microsoft untuk melatih komputer untuk berbagai tugas.
Langkah Google dan Microsoft ini meramaikan persaingan dalam menanamkan pengaruh dan menciptakan tenaga-tenaga ahli di bidang machine learning, setelah sebelumnya di awal tahun ini Facebook juga membuka Torch , sistem deep-learning mereka. Sedangkan bagi Microsoft, strategi ini adalah langkah lebih jauh untuk menarik para developer, setelah mereka melengkapi Azure dengan kemampuan machine learning dalam cloud.
Saat ini DMTK sudah tersedia di github dengan lisensi MIT.
Contributor :Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.

Kini Anda pun Bisa Ikut Mengembangkan Google Machine Learning Engine

Baru-baru ini Google mengumumkan bahwa mereka membuka TensorFlow menjadi open source dengan lisensi Apache 2.
Tensor Flow sendiri adalah machine learning engine yang dipakai Google di banyak aplikasi mereka, mulai dari pengenalan suara, SmartReply yang membantu pengguna dengan mengidentifikasi email penting sekaligus memberikan usulan balasannya, pengenalan gambar yang memungkinkan kita melakukan pencarian berdasarkan foto, mengenali dan menerjemahkan tulisan dari sebuah foto, dan lain-lain.
Menurut Google, engine ini dapat digunakan baik dalam riset maupun komersial, mulai dari mesin besar sampai telepon genggam. TensorFlow menggunakan metode deep learning dalam prosesnya, namun dapat juga menggunakan reinforcement learning and logistic regression.
Tentunya tidak semua aspek dari machine learning engine ini dibuka untuk umum. Saat ini hanya beberapa algoritma saja yang dicakup dalam paket open source ini. Dan tentunya Google tidak membuka arsitektur dari infrastruktur luar biasa canggih di balik engine tersebut. Versi open source ini pun adalah versi yang hanya akan berjalan di single computer, bukan yang bisa berjalan di jaringan yang besar. Namun demikian, langkah ini tetaplah sebuah langkah yang luar biasa, mengingat TensorFlow adalah bagian dari aplikasi inti Google saat ini.
Dengan langkah ini Google mengharapkan akan banyak pihak yang ikut mengembangkan teknologi Artificial Intelligence, terutama dengan menggunakan tools mereka. Dengan demikian diharapkan teknologi ini dapat berkembang dengan lebih cepat. Cara ini juga diharapkan dapat mencetak banyak ahli di bidang AI, dan membantu Google untuk menemukan calon-calon potensial untuk ditarik bekerja di Google.
Google sudah mempersiapkan website yang dilengkapi dengan tutorial dan dokumentasi untuk mulai mempelajari machine learning. Kini siapapun dapat ikut serta mengembangkan TensorFlow, termasuk anda.
Selamat belajar!
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng.
Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun.
Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.

Pivotal Analytics Engine Memperkuat Ekosistem Open Source Hadoop

Akhir september 2015 lalu, Pivotal mengumumkan telah menyumbangkan HAWQ dan MADLib kepada dunia open source melalui Apache Software Foundation. Pivotal merupakan sebuah perusahaan penyedia perangkat lunak dan layanan pengembangan aplikasi untuk data dan analisis berbasis teknologi komputasi awan.
Apache HAWQ, diluncurkan pertama kali tahun 2013 dengan nama Pivotal HAWQ, yang dibangun berdasar pengetahuan dan pengalaman yang diperoleh dari pengembangan data warehouse sistem Pivotal Greenplum dan PostgreSQL. Apache HAWQ menyediakan kemampuan untuk melakukan query dengan antarmuka SQL pada Hadoop secara native. HAWQ dapat membaca dan menulis data dari HDFS.
Apache HAWQ memiliki beberapa keunggulan :
1. Kinerja yang sangat tinggi
Arsitektur pemrosesan paralel HAWQ memberikan throughput kinerja tinggi dan waktu respon yang cepat, berpotensi mendekati real time, dan dapat menangani data berskala petabyte, serta beroperasi secara native dengan Hadoop.
2.ANSI SQL
mendukung antarmuka SQL, yang tentu saja akan mudah diintegrasikan dengan aplikasi lain termasuk BI/visualisasi tools, serta mampu mengeksekusi query yang kompleks.
3. Integrasi dengan Ekosistem Hadoop.
Terintegrasi dan dapat dikelola melalui YARN, serta dapat diinstal dengan AMBARI. HAWQ juga mendukung Parquet, AVRO, HBase dan lainnya. HAQW mudah diupgrade untuk menjaga kinerja dan kapasitas melalui penambahan nodes.
MADlib merupakan machine learning library untuk SQL yang terintegrasi dengan HAWQ. MADlib dikembangkan oleh Pivotal, bekerjasama dengan peneliti dari Unversitas California, Berkeley, Universitas Standford, Universitas Florida dan klien dari Pivotal. MADlib telah digunakan di bidang finansial, otomotif, media, telekomunikasi dan industri transportasi.
Dalam press release yang diumumkan melalui pivotal.io, Gavin Sherry, Vice President dan CTO Pivotal, berkeyakinan bahwa teknologi HAWQ dan MADlib sebagai proyek inkubasi Apache akan memberikan kemampuan pemrosesan SQL yang belum pernah terjadi sebelumnya kepada pengembang dan pengguna Hadoop.
sumber :
http://pivotal.io/big-data/press-release/pivotal-open-sources-top-analytics-engine
http://hawq.incubator.apache.org/
http://madlib.incubator.apache.org/
Contributor :

pecinta astronomi yang sejak kecil bercita-cita menjadi astronaut, setelah dewasa baru sadar kalau tinggi badannya tidak akan pernah cukup untuk lulus seleksi astronaut.