
Setelah pada tutorial lalu kita membahas mengenai instalasi Hadoop single node, kali ini kita akan membahas langkah instalasi Hadoop cluster di dalam VMWare.
Sebagai catatan, karena pada tutorial ini kita akan menjalankan 3 buah virtual machine secara bersamaan, maka PC atau laptop yang akan digunakan haruslah memiliki setidaknya 8 GB RAM, dan alokasi total untuk ke 3 VM ini sebaiknya tidak melebihi 4GB.
Berikut ini langkah instalasi Hadoop di Ubuntu 14.04 vmWare. Dalam tutorial ini digunakan hadoop 2.6.0. Untuk konfigurasi ini kita akan menggunakan 1 server namenode dan 2 server datanode. Yang akan kita lakukan adalah menginstall 1 mesin sampai selesai, lalu copy 2 kali untuk mendapatkan 3 instance server, dan kemudian kita setting agar ke-3 nya dapat berkomunikasi satu sama lain.
| IP | Type Node | Hostname |
|---|---|---|
| 192.168.4.148 | Name node | ubuntu1 |
| 192.168.4.149 | Data node 1 | ubuntu2 |
| 192.168.4.155 | Data node 2 | ubuntu3 |
1. Install VMWare Player
Install VMWare player, tergantung OS host anda, 32 atau 64 bit : https://my.vmware.com/web/vmware/free#desktop_end_user_computing/vmware_player/6_02. Install Ubuntu
Install Ubuntu 14.04 di VMWare player, anda. Download iso image Ubuntu 14.04 LTS di http://releases.ubuntu.com/14.04/ (sekali lagi, perhatikan keperluan anda, 32 atau 64 bit OS) Agar dapat berkomunikasi satu sama lain, termasuk dapat diakses melalui puTTY, set network setting ke Bridged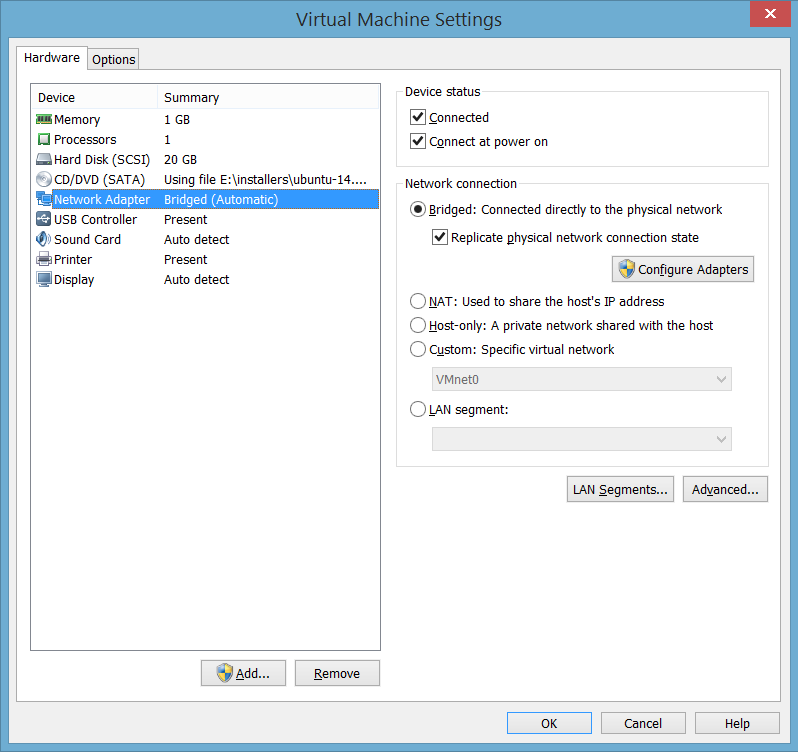
3. Install jdk
Ada beberapa pilihan yang bisa anda install, di antaranya openjdk atau oracle jdk. Untuk open jdk pilih setidaknya openjdk 7, dengan perintah sbb:
user@ubuntu:~$ sudo apt-get install openjdk-7-jdk |
Anda bisa juga menginstall jdk 7 oracle, dengan langkah sbb:
- download jdk 7 di http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html , sekali lagi, perhatikan kebutuhan anda 32 atau 64 bit
- upload ke ubuntu
- Extract package yang sudah diuplad tersebut
user@ubuntu:~$ tar xzvf jdk-7u79-linux-x64.tar.gz
- pindahkan ke direktori /usr/local/java
user@ubuntu:~$ sudo cp -Rh jdk1.7.0_79 /usr/local/java
5. Create dedicated group dan user untuk hadoop
Membuat user hduser dan group hdgroup untuk menjalankan hadoop. Langkah ini tidak harus dilakukan, tapi disarankan untuk memisahkan instalasi hadoop dengan aplikasi2 lain di mesin yang sama.
user@ubuntu:~$ sudo addgroup hdgroup user@ubuntu:~$ sudo adduser --ingroup hdgroup hduser |
user@ubuntu:~$ sudo adduser hduser sudo |
6. Setting jdk path Sebelumnya cek instalasi dengan perintah:
user@ubuntu:~$ java -version java version "1.7.0_79" Java(TM) SE Runtime Environment (build 1.7.0_79-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode) |
Login ke user hduser dengan perintah:
user@ubuntu:~$ su hduser |
Set JAVA_HOME di file .bashrc dengan memasukkan path yg sesuai, misalnya untuk java di direktori /usr/local/java , maka tambahkan baris berikut ini:
export JAVA_HOME=/usr/local/java
Apply setting dengan jalankan perintah berikut ini:
hduser@ubuntu:~$ . .bashrc |
7. Configure SSH
Hadoop memerlukan akses SSH untuk memanage node-node-nya. Kita perlu melakukan konfigurasi akses SSH ke localhost untuk user hadoop yang sudah kita buat sebelumnya, dan ke data node-nya nantinya.a. install ssh
hduser@ubuntu:~$ sudo apt-get install ssh |
b. generate an SSH key untuk user hadoop
hduser@ubuntu:~$ ssh-keygen -t rsa -P "" |
Perintah di atas akan membuat RSA key pair dengan password kosong. Sebenarnya penggunaan password kosong ini tidak disarankan dari sisi keamanan, namun dalam hal ini kita memerlukan akses tanpa password untuk keperluan interaksi Hadoop dengan node-node-nya. Tentunya kita tidak ingin memasukkan password setiap kali Hadoop mengakses node-nya, bukan?
c. enable akses SSH ke local machine dengan key yang baru dibuat
hduser@ubuntu:~$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys |
d. test setting SSH
Langkah terakhir adalah testing setup SSH tersebut dengan melakukan koneksi ke localhost menggunakan user hadoop. Langkah ini juga diperlukan untuk menyimpan host key dingerprint ke file known_host milik user hadoop.
hduser@ubuntu:~$ ssh localhost The authenticity of host 'localhost (::1)' can't be established. ECDSA key fingerprint is 34:72:32:43:11:87:fa:83:7e:ea:13:e6:43:68:28:0f. Are you sure you want to continue connecting (yes/no)? yes |
Langkah terakhir adalah testing setup SSH tersebut dengan melakukan koneksi ke localhost menggunakan user hadoop. Langkah ini juga diperlukan untuk menyimpan host key fingerprint ke file known_host milik user hadoop.
8. Instalasi Hadoop
Download hadoop di https://www.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz, extract ke sebuah direktori, misalnya /usr/local/hadoop.
hduser@ubuntu:~$ cd /usr/local hduser@ubuntu:~$ sudo tar xzf hadoop-2.6.0.tar.gz hduser@ubuntu:~$ sudo cp -Rh hadoop-2.6.0 /usr/local/hadoop |
Tambahkan baris berikut ini ke akhir file $HOME/.bashrc dari user hadoop. Jika anda menggunakan shell selain bash, maka anda perlu meng-update config file yang bersesuaian. Berikut ini setting untuk instalasi openjdk7:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END |
Untuk instalasi java di /usr/local/java, sesuaikan setting JAVA_HOME sbb:
export JAVA_HOME=/usr/local/javaCreate direktori untuk hadoop filesystem
Berikut ini beberapa direktori yang perlu dibuat untuk hadoop file system, yang akan di-set dalam parameter dfs.namenode.name.dir , dfs.datanode.name.dir di file
/usr/local/hadoop/etc/hadoop/conf/hdfs-site.xml dan parameter hadoop.tmp.dir di file /usr/local/hadoop/etc/hadoop/conf/core-site.xml: /app/hadoop/namenode, /app/hadoop/datanode dan /app/hadoop/tmp
hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/namenode hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/datanode hduser@ubuntu:~$ sudo chown hduser:hdgroup /app/hadoop/datanode hduser@ubuntu:~$ sudo mkdir -p /app/hadoop/tmp hduser@ubuntu:~$ sudo chown hduser:hdgroup /app/hadoop/tmp |
Update Hadoop File Configuration
Berikut ini beberapa file yang perlu di-update di direktori /usr/local/hadoop/etc/hadoop/etc/hadoopa. File hadoop-env.sh
hduser@ubuntu:~$ vi $HADOOP_INSTALL/etc/hadoop/hadoop-env.sh |
b. File-file *-site.xml
Dalam file /usr/local/hadoop/etc/hadoop/core-site.xml:Dalam file /usr/local/hadoop/etc/hadoop/mapred-site.xml:
Dalam file /usr/local/hadoop/etc/hadoop/conf/hdfs-site.xml:
Lho, gitu aja? Oh tentu tidak..!
Langkah selanjutnya akan dijelaskan pada bagian 2, so stay tune 🙂
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.