
Tutorial ini adalah kelanjutan dari Instalasi Hadoop Cluster di Ubuntu 14.04 VMWare. Diasumsikan bahwa Hadoop Cluster sudah disetting dan berjalan dengan baik seperti dalam tutorial tersebut.
Untuk dapat berjalan di atas cluster, Spark dapat dijalankan dengan menggunakan beberapa jenis cluster manager, yaitu Hadoop Yarn, Apache Mesos, ataupun cluster manager yang dimiliki Spark sendiri atau Spark stand alone cluster. Cluster manager ini yang akan mengalokasikan resource dalam cluster di mana Spark dijalankan. Untuk penjelasan lebih lanjut mengenai masing-masing arsitektur, dapat dibaca di sini
Untuk menjalankan spark dengan Spark cluster, berikut ini cara settingnya:Versi software yang digunakan adalah :
- Spark versi 1.4.1
- Scala 2.10.4
- Hadoop 2.6.0
Berikut ini konfigurasi cluster-nya:
| IP | Type Node | Hostname |
|---|---|---|
| 192.168.4.148 | Hadoop Name node / Spark Master | ubuntu1 |
| 192.168.4.149 | Hadoop Data node 1 / Spark Worker | ubuntu2 |
| 192.168.4.155 | Hadoop Data node 2 / Spark Worker | ubuntu3 |
- Download Apache Spark binary distribution dari siteApache Spark. Pilih spark distribution 1.4.1, Package type Pre-built for Hadoop 2.6 and later.
- Download Scala 10.2.4
- Extract package
- Update file .bashrc. Tambahkan 3 baris berikut ini ke akhir file $HOME/.bashrc dari user hadoop. Jika anda menggunakan shell selain bash, maka anda perlu meng-update config file yang bersesuaian export SCALA_HOME=/usr/local/scala
- Create direktori /home/hduser/sparkdata
- Sesuaikan file-file konfigurasi
- Jalankan spark master dan worker
- Spark Shell dan Web Interface
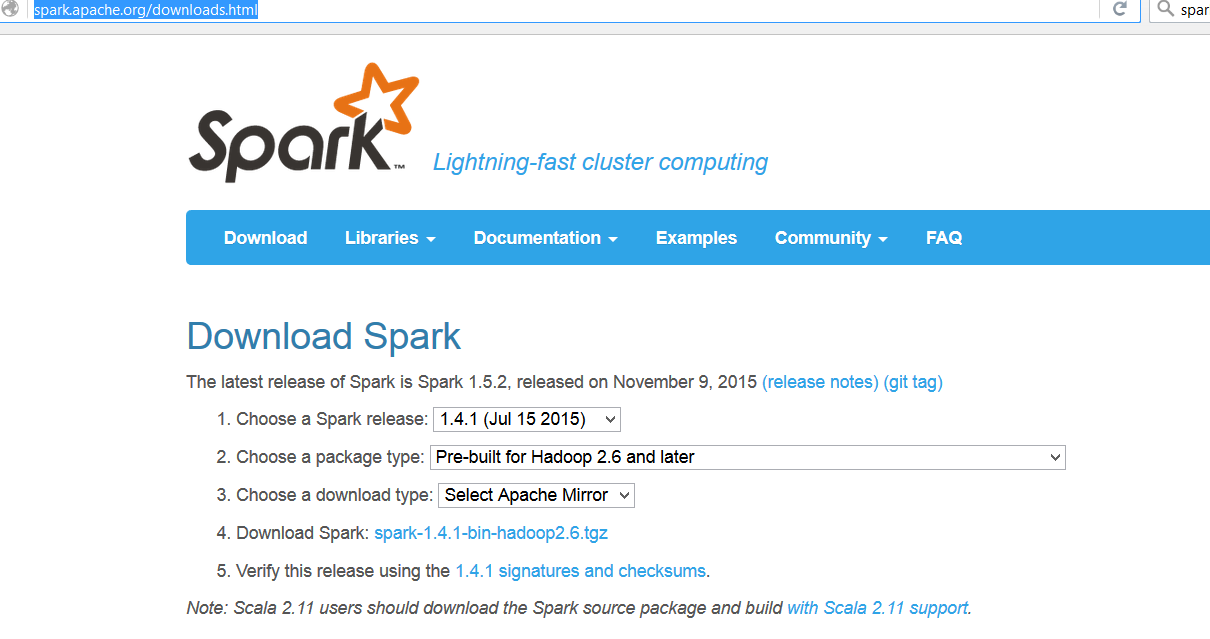
Bisa juga langsung dengan perintah berikut di salah satu mesin,
hduser@ubuntu1:~$ wget http://www.apache.org/dyn/closer.lua/spark/spark-1.4.1/spark-1.4.1-bin-hadoop2.6.tgzLalu distribusikan ke mesin yang lain dengan perintah scp
hduser@ubuntu1:~$ scp spark-1.4.1-bin-hadoop2.6.tgz hduser@ubuntu2:/home/hduser/hduser@ubuntu1:~$ scp spark-1.4.1-bin-hadoop2.6.tgz hduser@ubuntu3:/home/hduser/
hduser@ubuntu1:~$ wget http://www.scala-lang.org/files/archive/scala-2.10.4.tgz
Lalu distribusikan ke mesin yang lain dengan perintah scp
hduser@ubuntu1:~$ scp scala-2.10.4.tgz hduser@ubuntu2:/home/hduser/hduser@ubuntu1:~$ scp scala-2.10.4.tgz hduser@ubuntu3:/home/hduser/
Extract package spark di atas, dan pindahkan ke direktori /usr/local/spark
hduser@ubuntu1:~$ tar xzvf spark-1.4.1-bin-hadoop2.6.tgzhduser@ubuntu1:~$ sudo mv spark-1.4.1-bin-hadoop2.6 /usr/local/spark
Extract package scala di atas, dan pindahkan ke direktori /usr/local/scala
export SPARK_HOME=/usr/local/spark export PATH=$HOME/bin:$SCALA_HOME/bin:$PATH
Load setting dengan perintah
hduser@ubuntu1:~$ . ~/.bashrc
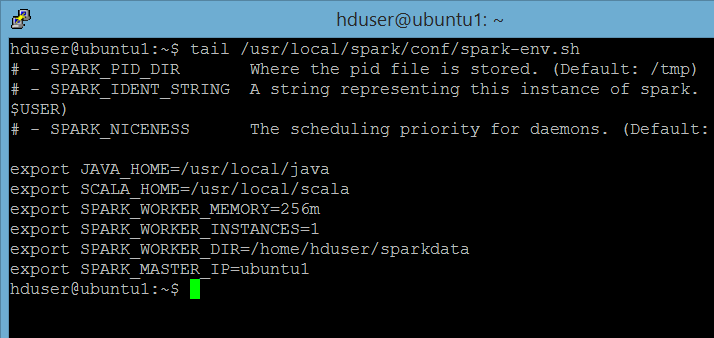
file /usr/local/spark/conf/spark-env.sh
export SCALA_HOME=/usr/local/scalaexport SPARK_WORKER_MEMORY=256m export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_DIR=/home/hduser/sparkdata export SPARK_MASTER_IP=ubuntu1
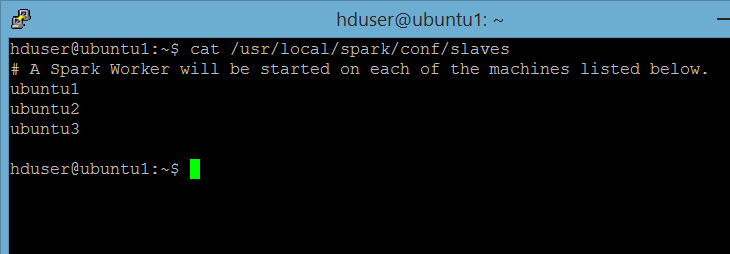
hduser@ubuntu1:~$ cp /usr/local/spark/conf/slaves.template /usr/local/spark/conf/slaves (copy file slaves.template ke file slaves)
ubuntu1ubuntu2 ubuntu3
file /usr/local/spark/conf/spark-defaults.conf.template
spark.master spark://ubuntu1:7077
Lakukan langkah 2-6 di atas untuk ke 2 server yang lain.
Untuk menjalankan spark master dan node, jalankan perintah berikut di mesin master (ubuntu1) :
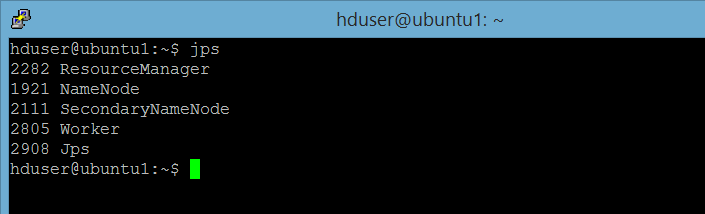
hduser@ubuntu1:~$ /usr/local/spark/sbin/start-all.shCek apakah master dan node sudah jalan, dengan perintah berikut:
hduser@ubuntu1:~$ jpsUntuk server master, akan tampak service-service berikut ini (catatan: dfs dan yarn sudah di-start sebelumnya)
Untuk node worker, sbb:

Untuk melihat web interface monitoring, jalankan spark-shell dengan perintah berikut ini:
hduser@ubuntu1:~$ /usr/local/spark/bin/spark-shellDi scala shell, jalankan perintah berikut ini:
|
scala> val input = sc.textFile("hdfs://ubuntu1:54310/data/README.txt")
scala> val words = input.flatMap(line => line.split(" ")) scala> val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y} scala> counts.collect() |
Akan muncul log dan hasil count yang dimunculkan sebagian sbb:
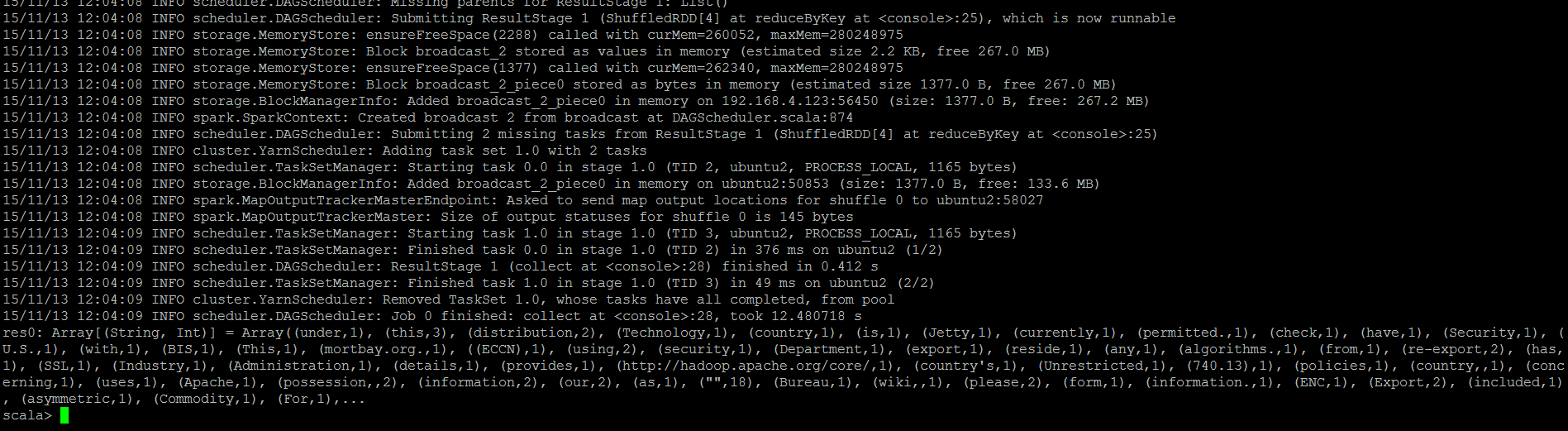
Jalankan perintah berikut ini untuk menyimpan output ke hdfs:
| scala> counts.saveAsTextFile("hdfs://ubuntu1:54310/data/testSave") |
scala> counts.saveAsTextFile("hdfs://ubuntu1:54310/data/testSave")
Untuk mengecek apakah file terbentuk, jalankan perintah berikut dari dari unix shell:
hduser@ubuntu1:~$ hadoop fs -ls /dataFound 2 items -rw-r--r-- 2 hduser supergroup 1366 2015-11-13 11:21 /data/README.txt
drwxr-xr-x - hduser supergroup 0 2015-11-13 12:06 /data/testSave
Bisa juga dengan menggunakan web interface hadoop di ubuntu1:50070, menu Utilities → Browse the File System

Untuk melihat isi file, gunakan perintah berikut:
hduser@ubuntu1:~$ hadoop fs -cat /data/testSaveUntuk melihat perintah lain yang dapat dilakukan di hadoop, gunakan perintah hadoop fs -help
Semoga bermanfaat 🙂
Contributor :
Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng. Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun. Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.