
Akhir tahun 2017 lalu Apache Foundation mengumumkan rilis Hadoop 3.0. Versi pertama dari Hadoop generasi ke 3 ini membawa banyak peningkatan dan penambahan fitur baru yang bukan hanya penting, namun juga sangat menarik.
Andrew Wang, rilis manager Apache Hadoop 3.0 menyebutkan bahwa Hadoop 3 “Merupakan hasil kerja sama dari ratusan kontributor dalam kurun lima tahun sejak Hadoop 2.” dan mencakup lebih dari 6000 perubahan sejak dimulainya pengembangan Hadoop 3 ini satu tahun yang lalu.
Berikut ini beberapa diantara berbagai fitur utama yang menjadi kekuatan Hadoop 3 :
-
Erasure-Coding
Apache Hadoop 3.0 menambahkan erasure-coding ke dalam pilihan mekanisme penyimpanannya. Fitur ini memberikan penghematan overhead storage sampai 50% dibandingkan dengan mekanisme replikasi standard HDFS. Namun penghematan ini tidaklah bebas biaya, karena sistem erasure-coding ini memiliki kompleksitas tambahan pada saat failure recovery. Oleh karena itu mekanisme EC ini sangat sesuai diterapkan pada data yang sudah lebih jarang diakses (colder data), misalnya untuk keperluan data archive. Pemanfaatan data tiering dan mekanisme erasure coding ini dapat menjawab kebutuhan untuk mengatasi permasalahan data sprawl. -
YARN-Federation
Saat ini mulai banyak organisasi atau perusahaan yang memiliki lebih dari 1 cluster Hadoop untuk keperluan-keperluan yang berbeda, namun masing-masing cluster masih berdiri sendiri. Fitur Yarn federation memungkinkan kita untuk mengatur banyak cluster dalam satu layer. Cluster-cluster tersebut akan menjadi sub-cluster di bawah Yarn-federation. Hal ini selain memudahkan dalam hal pengaturan juga memungkinkan untuk memanfaatkan cluster-cluster ini dengan jauh lebih optimal. Dengan fitur ini skalabilitas Hadoop juga meningkat tajam, dari semula 10 ribu nodes menjadi ratusan ribu.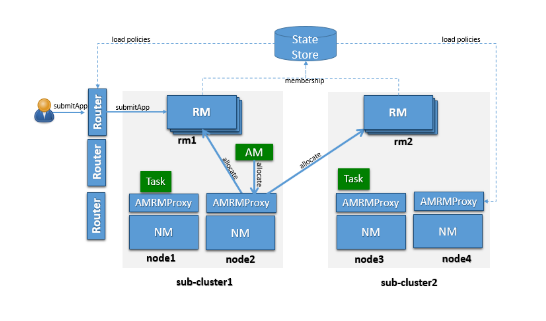
-
Extensible Resource Type
Kebutuhan terhadap tenaga komputasi semakin meningkat seiring dengan berkembangnya penerapan AI, khususnya deep learning dalam berbagai bidang. Sebuah sistem big data dituntut untuk dapat memanfaatkan berbagai sumber daya untuk mendukung kebutuhan komputasi yang semakin tinggi. Saat ini telah banyak banyak framework deep learning memanfaatkan GPU dan FPGA untuk keperluan komputasi yang intensif. Hadoop 3 memperluas kemampuan YARN untuk dapat memanfaatkan resource GPU dan FPGA, serta mengatur penggunaannya secara elastis untuk berbagai unit bisnis yang memerlukannya.
Versi 3.0 sudah mengimplementasi framework ini, namun implementasi untuk GPU baru akan dilakukan untuk versi 3.1 dan dukungan untuk FPGA pada versi 3.2. Kedua versi tersebut dijadwalkan akan dirilis pada tahun 2018 ini. -
Namenode High Availability
Hadoop 2.0 mendukung deployment 2 NameNode dalam 1 cluster (1 aktif, 1 standby), Hadoop 3.0 memungkinkan untuk memiliki lebih dari 1 standby namenode, sehingga kita bisa mendapatkan availability dan failover yang jauh lebih baik.
Tampaknya komunitas Hadoop berencana untuk mempercepat pengembangan Hadoop 3.x. Hal ini tampak dari rencana dua dot rilis pada tahun 2018 ini. Beberapa fitur menarik yang perlu kita nantikan di antaranya adalah support GPU dan FPGA, serta Yarn service framework, yang salah satunya akan mensupport service-service yang berjalan dalam waktu yang relatif lama seperti service HBase, Hive/LLAP dan service berbasis container (misalnya Docker).
Berbagai fitur maupun roadmap tersebut dapat dilihat sebagai jawaban atas berbagai tantangan yang muncul akhir-akhir ini, terutama dua tahun terakhir ini. Salah satunya adalah banyak pihak yang menyebut era big data saat ini sebagai ‘era paska Hadoop’, yang menunjukkan bahwa banyak pihak mulai menganggap bahwa Hadoop sudah tidak terlalu sesuai lagi dengan kebutuhan dan trend big data saat ini.
Seperti yang diungkapkan oleh Vinod Vavilapali, Hadoop YARN & MapReduce Development Lead di Hortonwork : “Dengan Hadoop 3, kita bergerak ke skala yang lebih besar, efisiensi penyimpanan yang lebih baik, dukungan deep learning/AI dan juga interoperabilitas dengan cloud. Dalam waktu dekat ini terdapat item roadmap untuk menjalankan containerized-workload pada cluster yang sama, dan juga berbagai API untuk penyimpanan objek.
Dengan semua ini, kita akan melihat Hadoop menjadi lebih kuat, yang memungkinkan berbagai use-case mutakhir, dan dengan demikian Hadoop mungkin juga akan menjadi mudah dan membosankan.
Terlepas dari itu, berbagai penemuan dan pengembangan baru ini menunjukkan bahwa Hadoop akan selalu relevan dan menjadi latar belakang bagi berbagai infrastruktur penting yang di dunia yang semakin data-driven ini.”
Contributor :

Penyuka kopi dan pasta (bukan copy paste) yang sangat hobi makan nasi goreng.
Telah berkecimpung di bidang data processing dan data warehousing selama 12 tahun.
Salah satu obsesi yang belum terpenuhi saat ini adalah menjadi kontributor aktif di forum idBigdata.