
Implementasi
Implementasi dilakukan dengan memanfaatkan HGrid247 sebagai Big Data engineering tools, yang mendukung pemrosesan dengan MapReduce. Dengan memanfaatkan HGrid247, implementasi sequence alignment dapat dilakukan secara modular, dan dapat memanfaatkan komponen-komponen yang telah ada di HGrid247.Untuk mengimplementasikan sequence alignment workflow, penulis menambahkan beberapa komponen, yaitu komponen parsing input data, komponen untuk proses alignment, dan komponen untuk formatting output.
Workflow yang dihasilkan adalah seperti di bawah ini:
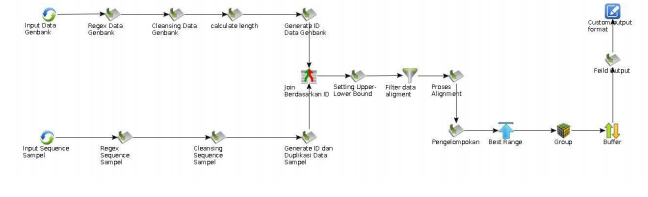
- Data preprocessing : pemrosesan data genbank dan data sample (data input yang akan diproses), sebelum dilakukan alignment.
- Filter data genbank, berdasar panjang sekuens yang akan di-align, ditentukan dengan batas atas dan batas bawah. Untuk proses global alignment, idealnya dilakukan antar sekuens yang panjangnya hampir sama, sebab untuk sekuens dengan selisih panjang yang besar, hasil score alignment akan kurang bagus dan akan tersisihkan.
- Alignment dan formatting output.
Ujicoba dilakukan pada dua environment, yaitu :
- Local Node
- Hadoop cluster
Software yang digunakan adalah HGrid247-2.3.2, dan cluster menggunakan Hadoop version 2.5.0 (distro Cloudera versi 5.2.0).
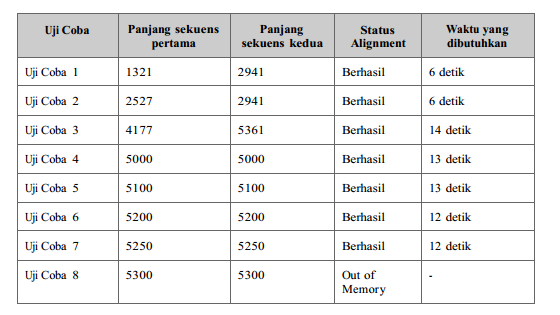
Hasil uji coba pada local node
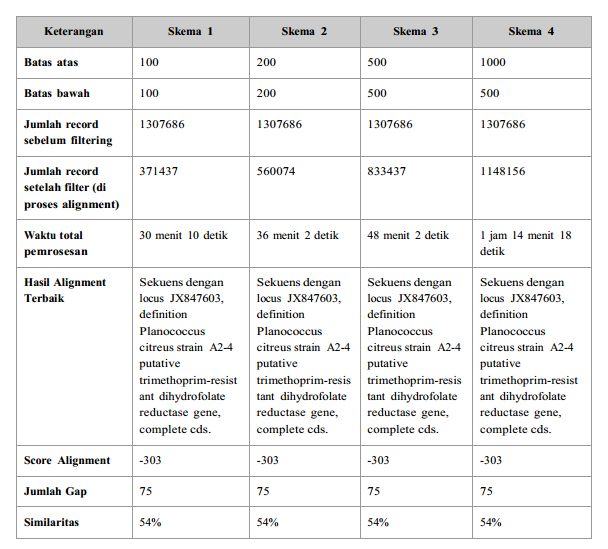
Hasil uji coba pada cluster
Dalam uji coba ini digunakan data sample berupa sekuens yang berasal dari mamalia yaitu locus X71497, definition B.taurus microsatellite sequence INRA053. Accession X71497, version X71497.1 GI:509111, dan source Bos taurus (cattle).Pada uji coba ini yang divariasikan adalah batas atas dan batas bawah yang menentukan data reference yang akan diikutsertakan dalam proses multipairwise alignment. Semakin besar nilainya, maka jumlah record dari genbank yang akan dibandingkan dengan data sample akan semakin besar.
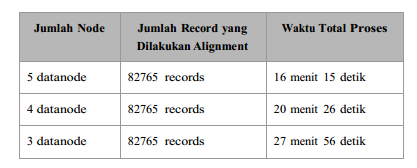
Uji coba dengan variasi jumlah node
Pada uji coba ini jumlah node yang digunakan dalam cluster divariasikan.
Dengan menggunakan teknik iteratif pada algoritma Needleman Wunsch, kejadian stack overflow dapat dihindari.
Penggunaan paralel processing memungkinkan dilakukannya multipairwise alignment dengan waktu yang jauh lebih singkat. Waktu yang diperlukan untuk melakukan alignment berbanding terbalik dengan jumlah node yang digunakan. Dengan arsitektur Hadoop yang scalable secara linear, penambahan kapasitas pemrosesan cukup dilakukan dengan penambahan node saja.Dengan memanfaatkan HGrid247 sebagai tools data processing, dapat meminimalisasi implementasi, dengan cara memanfaatkan komponen-komponen yang telah ada dan dapat menambahkan komponen yang belum ada jika diperlukan. Antarmuka grafis memudahkanvariasi proses, di mana perubahan flow dan parameter dapat dilakukan dengan relatif lebih mudah.
Dari sisi algoritma, untuk melakukan multipairwise alignment cukup dengan melakukan 1 kali traceback dengan kondisi parameter input untuk gap opening dan gap extension sama. Hal ini dikarenakan traceback dimulai dari nilai optimum, dan nilai tersebut merupakan nilai optimum score alignment, sehingga semua traceback akan memiliki nilai score alignment yang sama.